

We've raised $275 million to build the next generation of AI Inference
Hello Reader,
We knew that the demand for AI inference would explode as models matured and more use cases emerged—and that GPUs weren’t going to cut it when we hit that point—from day one.
Well, we’ve reached that point. Users are demanding high-quality, interactive applications with significantly lower latency and snappy performance. Energy consumption is ballooning, and GPUs are sitting in data centers under-utilized even in their most optimal configurations and missing the opportunity to deliver delightful experiences.
We’re working to build something to deliver that exact experience in a wholly sustainable format in cost, energy consumption, and interoperability. And we’ve raised a brand new funding round to accelerate that work: our $275 million Series C at a $2 billion valuation.
Corsair is designed to create high-quality interactive experiences with high-performance, memory-optimized small-batch AI inference. And we’ve launched our own transparent NIC solution to accelerate that in JetStream, as well as a rack-scale qualified blueprint in SquadRack.
We still have a lot of work to do, and we’re excited to see how the AI landscape continues to evolve. Thank you to everyone who’s come along for the ride.
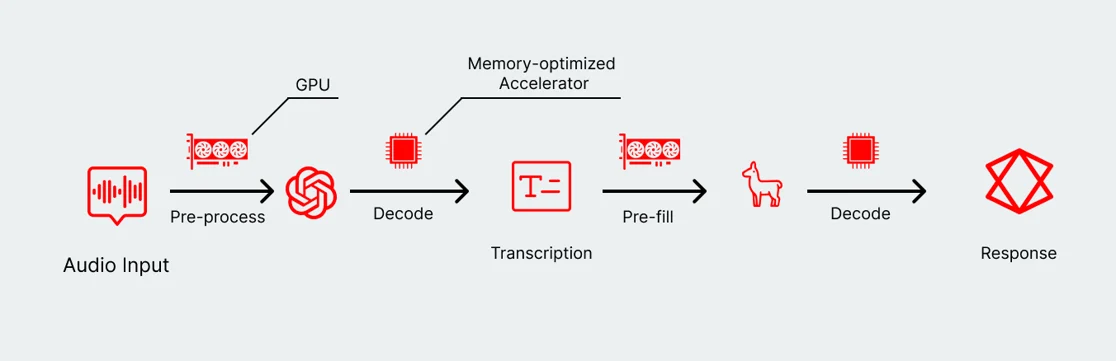
Modern AI workloads demand a disaggregated approach
GPU-only pipelines, while simple to implement, are increasingly missing out on the opportunity to create a tighter user experience. The architectural differences between the two phases of AI inference—pre-fill and decode—are exposing the weaknesses of homogenous pipelines.
There's a new opportunity to dedicate specific hardware (and configurations of that hardware) to specific phases of AI inference. Rather than just assign a model to a GPU or some custom accelerator, developers can go even deeper to improve the user experience by selecting unique hardware for each phase of AI inference.
Interested in more from d-Matrix?
Get the latest d-Matrix updates to your inbox. Sign up below:
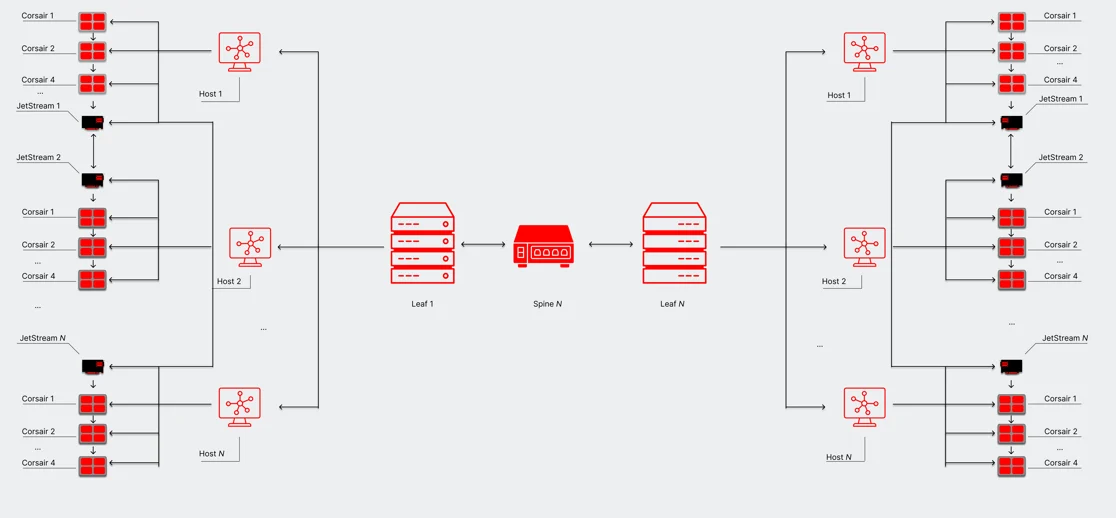
Peeking under the hood of JetStream, our transparent NIC solution
We built JetStream to extend our Corsair AI inference system to a rack-scale level to support larger models while maintaining the same extreme performance requirements we set for ourselves. Read more on some of the challenges of building JetStream and the exact problems it's tackling.
See us at Supercomputing 2025
d-Matrix will be attending SC25 at booth 2938. Come say hi to the team and learn more about Corsair and how we are powering the next generation of generative AI.
Our new partnership with AIchip
We're excited to announce our partnership with AI infrastructure leader AIchip to build our stacked 3D DRAM, 3DIMC, solution for next-generation AI inference.

Our new partnership with AIchip 2
We're excited to announce our partnership with AI infrastructure leader AIchip to build our stacked 3D DRAM, 3DIMC, solution for next-generation AI inference.