
Corsair™. Built for
Generative AI
- Unique Digital-In Memory Compute Architecture
- Integrated Performance Memory for Blazing Fast Speed
- Off-chip Capacity Memory for Offline Batched Inference
- Block Floating Point Numerics for Efficiency
- Scale-out from Card to Rack with Standard Fabrics

Scale your inference-time compute fearlessly to unlock new levels of autonomy and intelligence with Corsair and JetStream!

Meet skyrocketing AI demands with JetStream™, purpose-built I/O accelerator for AI inference
Power AI operations with millions of requests using our custom NIC built for accelerator-to-accelerator communications.
- Deploy AI with blazing fast multi-node scale-up
- PCIe form factor for easy plug-and-play with existing datacenter infrastructure
- Built for ethernet-based open standards

Corsair Dual Card
- 6400 mm2 silicon
- 4800 TFLOPs MXINT8 dense
- 19200 TFLOPs MXINT4 dense
- 4 GB Performance Memory @ 300 TB/s
- Up to 512 GB Capacity Memory
- 512 GB/s card-to-card DMX Bridge™
Blend of cutting-edge innovations in a industry standard FHFL PCIe card, connected as a pair with high-bandwidth DMX Bridge™
Inference Server
- 8 cards*
- 19.2 PFLOPs MXINT8 dense
- 76.8 PFLOPs MXINT4 dense
- 16 GB Performance Memory @ 1200 TB/s
- Up to 2 TB Capacity Memory
- PCIE based scale-up
High compute and memory density and card-to-card connectivity for efficient AI inference
*reference configuration
Inference Rack
- 8 servers (64 cards)*
- 128 GB Performance Memory @ 9.6 PB/s
- Up to 100B models in Performance Mode
- Up to 16.4 TB Capacity Memory
- 1T+ frontier models in Capacity Mode
- Scale-out over PCIe or Ethernet
Ideal for both high interactivity and offline batched use cases deployed at scale.
*reference configuration
Corsair is the first-of-its-kind AI compute platform. It offers unparalleled performance and efficiency for generative AI inference in the datacenter.
Ideal for tomorrow’s use cases where models will “think” more. Supercharging reasoning, agents and video generation.
Blazing Fast
interactive speed
Commercially Viable
cost-performance
Sustainable
energy efficiency




Aviator software:
The only way to pilot your model
Corsair’s architecture was designed with software in mind. Our Aviator software stack is performant and easy to use, offering a seamless user experience.
Aviator Software
Integrates with broadly adopted open frameworks such as PyTorch and Triton DSL to allow developers to easily deploy their model. Built with open-source software such as MLIR, PyTorch, OpenBMC.

How it works
Hover over icons for more information
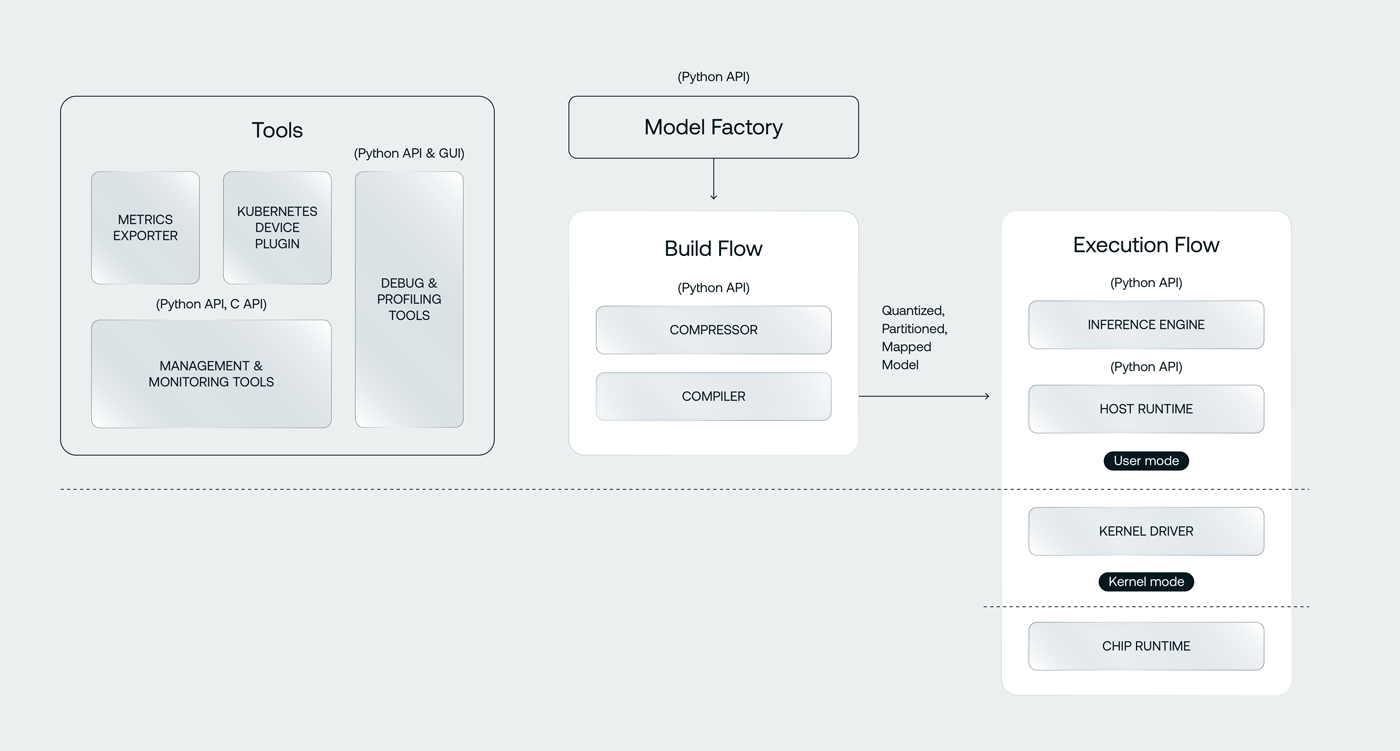
Tools
A comprehensive suite of tools to deploy and monitor d-Matrix cards, and analyze workload performance
Model Factory
A template of PyTorch models that enables distributed inference across multiple d-Matrix cards
Compressor
A model compression toolkit to enable efficient block floating point numerical formats supported by d-Matrix hardware
Compiler
A state-of-the-art compiler that leverages MLIR ecosystem and produces optimized code targeted for d-Matrix hardware
Inference Engine
A distributed inference execution engine that deploys inference requests efficiently to a cluster of d-Matrix hardware
Host Runtime
A runtime that manages host interaction with the d-Matrix cards
Chip Runtime
On-chip firmware that launches jobs asynchronously from the host and enables high utilization of the d-Matrix devices
Model Factory – A template of PyTorch models that enables distributed inference across multiple d-Matrix cards
Compiler – A state-of-the-art compiler that leverages MLIR ecosystem and produces optimized code targeted for d-Matrix hardware
Host Runtime – A runtime that manages host interaction with the d-Matrix cards
Chip Runtime – On-chip firmware that launches jobs asynchronously from the host and enables high utilization of the d-Matrix devices


