

Delivering high-quality AI-powered applications historically relied on massive models. That came with significant scaling limitations, as deploying models with more than 100B parameters and maximizing toke generation doesn’t scale up without losing latency or chewing up more power.
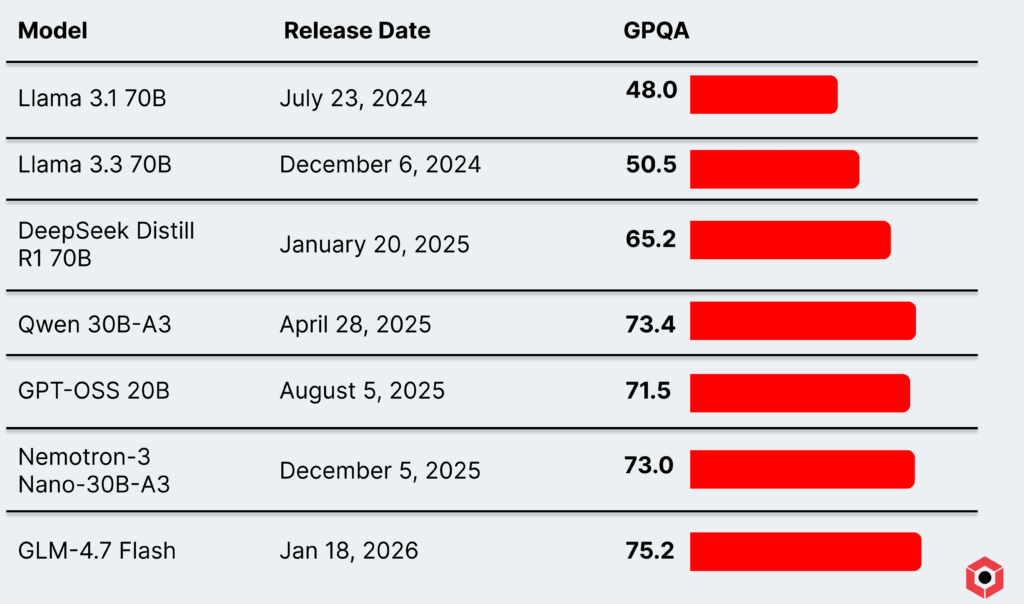
But smaller models today have since the launch of state-of-the-art-at-the-time dense models like Llama 3.1 70B and Llama 3.3 70B. Models like GPT-OSS 20B and Qwen’s mixture-of-experts models massively outperform older 70B-sized models on a variety of benchmarks.
Those models are also well-suited to power many—if not most—AI workloads at scale. They consume less power with a smaller compute footprint, can run on less hardware with a smaller memory footprint, and as a result can use hybrid memory approaches like a mixture of DRAM and SRAM.
That hardware optionality, along with a dearth of sub-100B models, has given enterprises a tantalizing option to scale up AI workloads that don’t need the firepower of a colossal model. And those smaller models are even more practical thanks to the new prevalence of agentic workloads.
How small models filled the gap
The same reasoning capabilities that power larger models like GPT-o1, DeepSeek V3 and R1, and others have trickled down to smaller, open source models as well. These models come with two main benefits: they have a smaller compute footprint (activating a small number of parameters), and they fit in a much smaller memory footprint.
But these models have proved quite capable as well! Compared to earlier massive models, modern smaller reasoning models like GPT-OSS 20B and Qwen 30B-A3-2507 massively outperform some 70B models released less than a year earlier. Llama 3.3 70B, which was seen as the standard when it came out, has since been eclipsed—and then some—by modern smaller mixture-of-expert models.
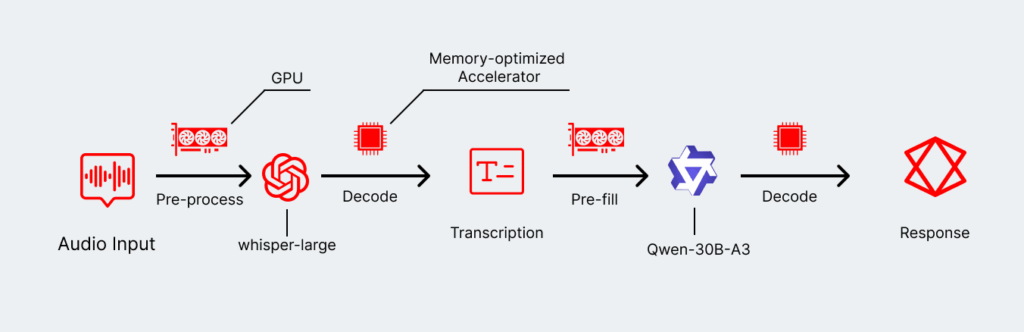
They’re especially well-suited to agentic networks, which break down what normally would have been a task for a much larger and more powerful model into smaller and more targeted chunks. Rather than feed an entire voice clip into a single model for processing and analysis, agentic flows enable highly optimized individual steps:
- Selecting the model of best fit for a given process, such as relying on a transcription model like Whisper rather than feeding the voice file into a larger model.
- Enabling fine-tuning of those individual models, which could provide significant performance benefits for highly specific enterprise use cases.
- Deploying a chain that is, in total, smaller and more efficient than a massive multi-modal model.
- Selecting individual hardware types that work well for some given model—or even the specific step of an inference.
These targeted models and disaggregated approaches pull each individual lever available to optimize the user experience. Users don’t necessarily care about one specific model, generating tens of thousands of tokens per second. Instead, the end-to-end speed is what matters, which forces developers to consider latency in addition to throughput.
There is one small catch, however: these smaller reasoning models do consume more tokens than some of the older dense models. But the nature of the size and power required, as well as the enormous performance bump, makes that issue a lot less daunting than it seems.
How smaller models will power the next generation of AI
Smaller models, by nature of requiring a smaller power and hardware footprint, can also maximize another one of the most important metrics for any enterprise: cost.
Balancing performance and cost become a crucial part of the process once these workloads start scaling up. A massive, do-it-all model might work for a smaller set of users. But once you are growing into the millions—or even billions—of users, every single fraction of a cent counts. That matters for companies relying on APIs and companies that are running their own hardware.
That kind of optimization can also become a breeding ground for an enormous amount of innovation. Enabling a greater swath of enterprises to work with extremely powerful tools expands the total surface area of what’s possible with AI. While many workloads today are very targeted—like code generation or customer service—experimentation will unlock even more in the future.
That starts, however, with finding that right balance for enterprises that want to get AI workloads into production. And that starts with making something practical, efficient, and flexible enough to create a high-quality user experience.


