

It's Primetime for SRAM
We’ve spent the last seven years building a groundbreaking system deploying a hybridized memory approach to create high-performance, extremely low latency systems. Thanks to the explosion of agentic usage in AI applications, that’s even more critical today.
Our focus on integrating SRAM has been the bedrock for all of this. It moves the memory right alongside compute, dramatically collapsing the distance data travels and enables the speed and latency that the next generation of AI workloads needs.
The next generation of workloads won’t be one giant frontier model handling everything. It will be a portfolio of models that each perform exceptionally well at a specific task, many of which will be small. Compute matters, but SRAM unlocks the real speed that AI inference needs to enable new products and scale them up.
And because SRAM dramatically reduces the energy cost of moving data, it directly addresses the power constraints that are already limiting how enterprises scale up AI infrastructure. Faster, more predictable, and more power-efficient — that’s the trifecta that makes the next generation of AI products viable at scale.
Modern AI workflows demand an enormous amount of flexibility, and the best way to handle that is by deploying a large portfolio of models into an agentic network. And smaller models are more powerful than ever, creating a massive opportunity to build a balanced approach that uses both DRAM and SRAM.
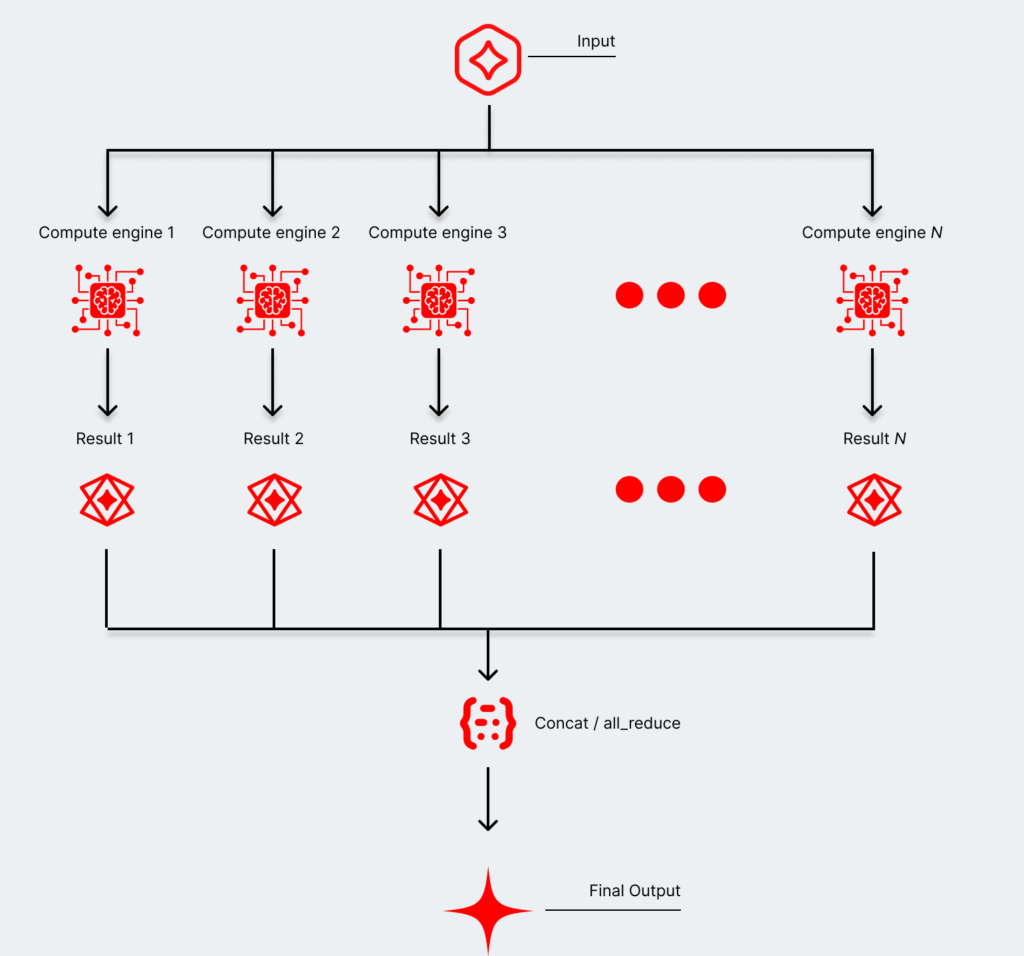
The massive opportunity to hybrid memory architecture
The growth of agentic AI applications is now exposing another gaping issue with classic GPU architectures: the tradeoffs between extreme token generation speeds and deploying massive models.
Maintaining that extreme token generation speed while using massive models creates an immediate bottleneck when using a typical HBM architecture. And while smaller models are more and more performant, growing those AI applications to millions of users presents a similar dilemma. But those tradeoffs are less extreme when taking a hybridized memory approach—particularly one balancing DRAM and SRAM.
See more about the benefits of using a hybridized memory approach—and why it offers the best path forward to deploying agentic-based AI applications at scale.
Interested in more from d-Matrix?
Get the latest d-Matrix updates to your inbox. Sign up below:

Why we bet on in-memory compute to power the future of AI inference
See a deep dive on our optimized memory infrastructure in an article from Frederic Lardinois over at The New Stack.

d-Matrix Spotlight: Powering the new Age of Inference
The d-Matrix leadership team were in India this month for AI Impact Summit 2026 exploring the next wave of innovation in AI powered by extremely low-latency inference.
Read why The Economic Times highlighted d-Matrix and our founders Sid Sheth and Sudeep Bhoja and their key role in shaping that wave.