Modern AI has finally enabled us to build advanced, seamless applications in final frontier of human interaction: phone calls.
Multimodal agentic AI applications have finally turned voice-based experiences from pulling teeth into a snappy, delightful experience. Achieving real customer service finally doesn’t include repeating the same command repeatedly until it automatically hangs up.
However, low-latency voice-enabled pipelines aren’t just relegated to customer service. They enable a whole universe of applications that you might not expect. One such example, taking advantage of two of AI’s most powerful mechanisms, is speech-to-code.
Speech-to-code can thrive on heterogeneous pipelines just like AI inference pipelines for customer service—where smaller models execute simpler tasks like speech transcription on optimized accelerators.
Where heterogeneous pipelines excel in speech
Rather than sitting in an IDE and rolling back and forth between a prompt box and a development environment, speech pipelines enable the process of telling a model to program something. As these models further improve, they require less handholding.
GPUs can take on every task in an AI inference pipeline, but they aren’t the best choice for all of them. They excel at the pre-fill stage of AI inference, but the actual decoding process becomes a tricky balance between latency and concurrency because of the constraints HBM presents.
Demand for AI inference, however, is exploding—and user expectations are only growing thanks to competition among the top model providers. Latency is now a determinant for the quality of a tool as much as the quality of the response. Agentic workflows split up a mammoth model call into simpler tasks. These pipelines can achieve similar—or often the same—quality results by opening up individual modalities and steps for smaller models.
That also enables GPUs to slot in where they work best while finding ways to optimize the individual smaller modalities, like speech-to-text or text-to-speech, on hardware that excels running those models. Heterogeneous pipelines are quickly becoming the answer to that problem.
Planning in front of a (virtual) whiteboard
Agentic tools like Claude Code can run off and do most of the work behind the scenes, but they still require planning ahead of time to perform best, as well as periodic check-ins. Extremely low-latency voice pipelines can make those conversations smoother and much more precise.
A snappy voice feedback loop can make it feel much more like you’re talking to a pair programmer, rather than assigning a task to a robot with a laundry list of tasks and waiting for a series of follow-ups.
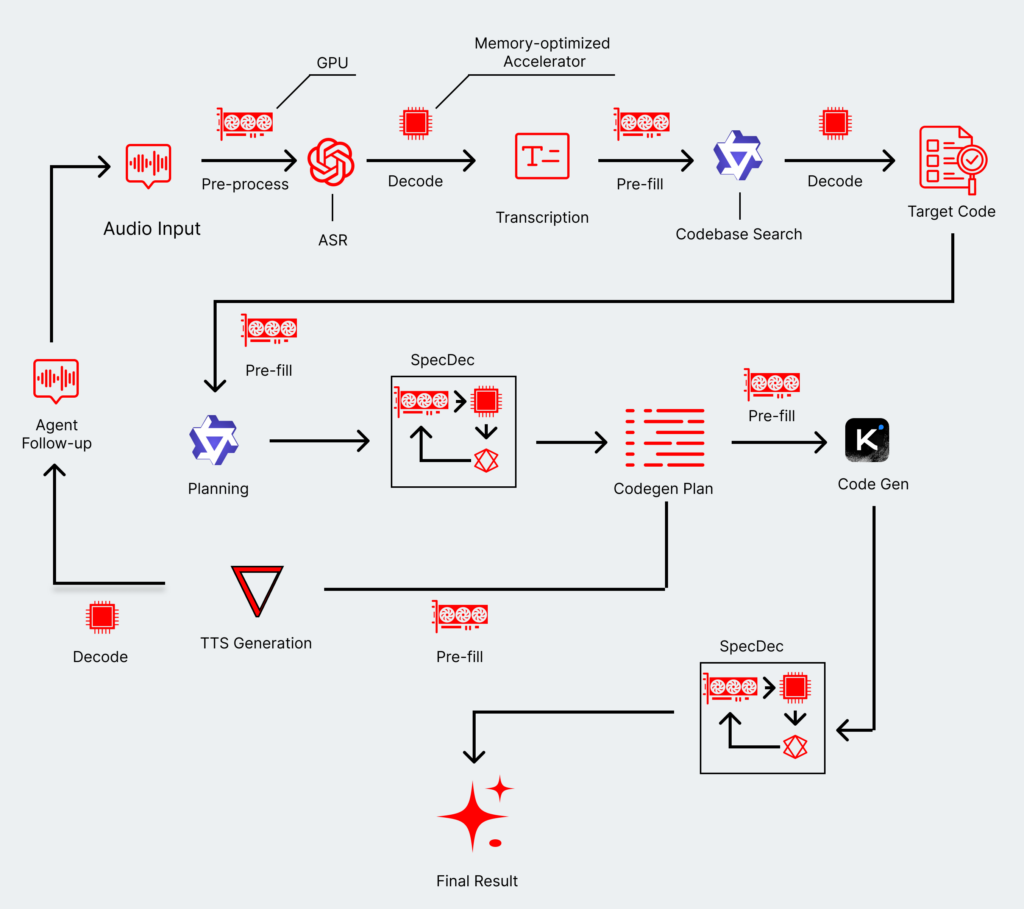
The process is essentially something similar to a customer service call — a back-and-forth discussion that executes RAG lookups, search, planning, and follow-up questions—but in a lifelike, high-bandwidth conversation rather than a slower call-and-response.
Once all that planning is done, the agent is off to the races.
Checking in on the road
You can already imagine plenty of settings where a speech-to-code pipeline might work.
It could obviously happen in front of a screen, where you’re commenting live on buildouts and modifications of HTML for a webpage. But it could also roll into a pair of headphones—or conference lines—that introduce a whole new way of interacting with the coding experience.
Generating code can happen in the middle of a commute (assuming you aren’t annoying those around you on the train). Or it can happen in the middle of a conference room where several people are making requests, adjustments, and comments for something on a screen in the room.
All these, however, are only possible if the experience is extremely fast and snappy. That’s only possible by optimizing whole parts of the pipeline by finding ways to drop the latency of individual steps as close to zero as possible. Heterogeneous pipelines, where optimized accelerators take over those steps, make that possible—and make it possible today.
Empowering next-generation AI inference use cases
Heterogeneous pipelines and custom accelerators aren’t just improving AI inference pipelines as they exist today (though they are still doing so). They’re enabling a whole potential universe of use cases and applications that are both extensions of the way we currently interact with applications (like speech-to-code) and brand-new experiences (like agentic design).
Speech-to-code also represents an enormous opportunity to make code generation and programming significantly more accessible. It improves the overall surface area of interaction for programming, working with a much wider potential user base that might not be able to do “classic” programming in front of an IDE.
The next generation of AI applications isn’t necessarily about building out wholly new unexpected experiences (though we are doing that). Optimizing existing processes with completely new modalities offers just as much opportunity—and heterogeneous pipelines make that a reality.