
Corsair at Rack Scale
Introducing SquadRack : a fully qualified purpose-built AI inference solution.




Enterprise-grade Agentic AI
Instantaneous Reasoning
Multimodal agents
Effortlessly deploy AI inference workloads
SquadRack provides customers with a turnkey blueprint to power the runaway demand for AI inference powered by Corsair and JetStream. Handle millions of requests per second and speed up time-to-inference.
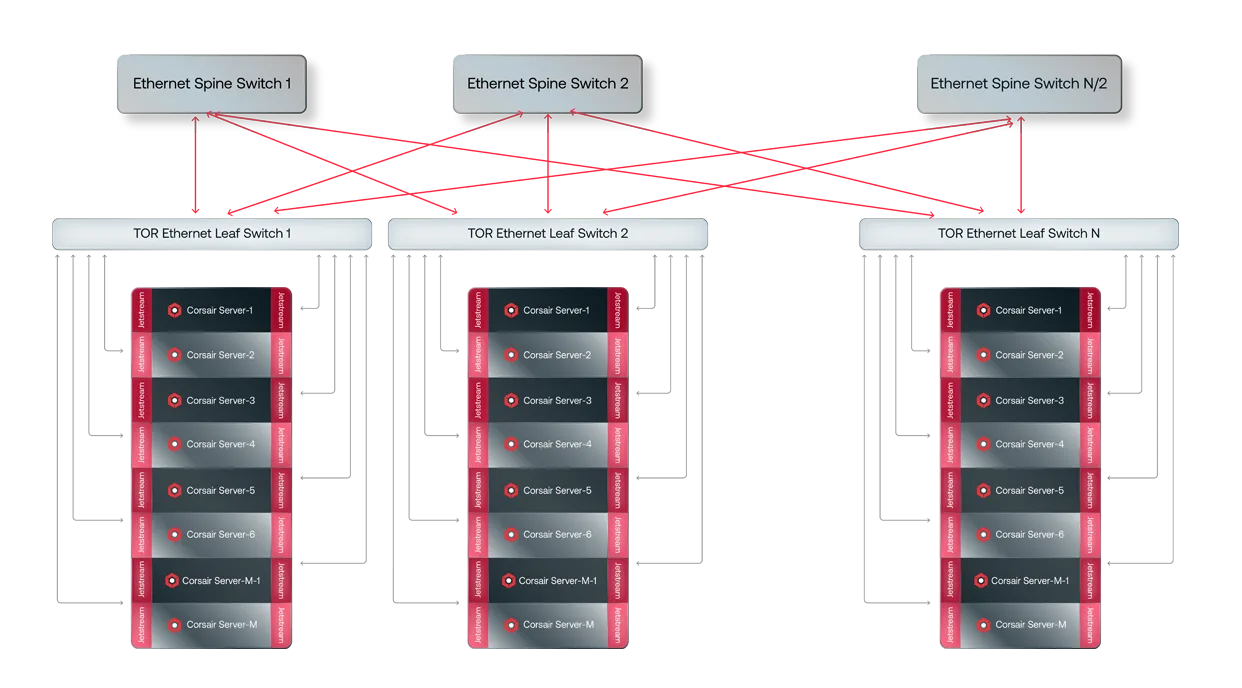
Flexibly scale AI your workloads
d-Matrix Corsair with JetStream combine to create a revolutionary scaling architecture to power larger models without any penalties to throughput or latency. Size the deployment footprint based on inference demand, and easily expand to more racks as demand grows.

Truly sustainable ultra-efficient inference
The SquadRack reference configurations guarantee stable performance across hundreds of nodes. Built with interoperability in mind for any data center architecture featuring air-cooled PCIe-based AI servers and standard ethernet leaf switches.

Built with open standards in mind
Today d-Matrix uses PCIe for scaling up within a single node and industry standard ethernet for both scaling up in a rack and scaling out across racks.
As a member of the UALink and UEC industry consortiums, d-Matrix is teaming up to work on the next generation of scale-up and scale-out standards.
Learn MoreConfigurable to your Data Center

Single-Server Starter Rack
8 Cards
- 16 GB Performance Memory @ 1,200 TB/s
- Up to 2TB Capacity Memory
- Best for multimodal agentic workflows
- Designed for Standard Density (<10KW)

Dual-Server Starter Rack
2 servers (16 cards)
- 32 GB Performance memory
- Supports multi-user applications
- Best for larger multimodal agentic workflow
- Designed for High Density (10-30KW)
- Ethernet-based scale out with JetStream

Multi-Server Half-Rack
4 servers (32 cards)
- 64 GB Performance Memory
- Longer context windows
- Best for distilled models, basic reasoning, and video gen
- Designed for Ultra-High Density (30-100KW)

Enterprise-Ready Full Rack
8 servers (64 cards)
- 128 GB Performance Memory
- Models up to 100B parameters in performance mode
- Designed for Enterprise-Ready Ultra-High Density
- Best for enterprise-grade model deployment
Scale up to Enterprise-Grade Configurations
Corsair with Jetsrteam scales up to any number of servers using a leaf/spine Ethernet-based scale-out architecture. Build clusters with your exact memory specifications without losing the ultra-low latency and performance of a single rack
Contact us to Learn More
