When we launched seven years ago, we had one goal: to build the fastest and most scalable technology to power small-batch AI inference and interactive applications.
Both of those have become absolute table stakes in the last 12 months as user expectations grow and tens of millions of people flock to interactive applications. Our approach involved deploying purpose-built SRAM-based inference architecture at scale to capture the steps in inference that needed to be completed fastest, were relatively low complexity, and captured a significant volume of the actual inference compute.
But to support the full scope of AI inference, including future innovations, we knew from the beginning that we would have to extend the same performance and low-latency Corsair has, but with larger memory capacity. To do that, we went vertical: adding an additional layer of DRAM on top of the compute.
Agentic pipelines are becoming increasingly sophisticated, and some steps will inevitably require larger models for quality purposes—such as translation or code completion. The same performance we bring to smaller models must inevitably extend to models at significantly larger scale, as well as even further optimize disaggregated inference pipelines.
Why memory was the blocker here—and will remain in the future
Our chiplet-based design with on-chip SRAM and PCIe-based architecture enables us to scale up the total memory pool available in SRAM linearly, with an additional pool of DRAM available when needed. This enabled several benefits:
- Ultra-low latency, particularly for task-specific steps in agentic pipelines where interactivity is the determining factor of success and single agentic steps can hold up the entire pipeline.
- Seamless scalability that enables us to grow to a rack-level pool of memory that can operate most models on rack-scale Corsair.
- Plug-and-play hardware that fits directly into most existing data center configurations with a low power envelope.
- Highly flexible in disaggregated pipelines that optimizes full pipelines by working in concert with other accelerators like GPUs to accelerate larger, more powerful models.
Smaller models, however, are only part of the solution—nor are they the only area where rapid innovation is happening. Frontier models as well as recent open-weight models like Qwen, Kimi and DeepSeek have delivered powerful reasoning capability for complex tasks but are sprawled into the hundreds of billions of parameters.
Scaling SRAM beyond a single die
It’s tempting to look at a chiplet design and say you’ve just split it into a bunch of tiny HBM-esque pipes rather than a single pathway.
But the problem itself has shifted to a different realm governed by die-to-die interconnectivity. SRAM access is still adjacent to compute on-die and operating at full speed. Scaling that up moves the challenge to a die-to-die architectural problem — when one chiplet needs data from a neighbor.
That shifts the problem space to a different set of metrics: bandwidth per millimeter of edge, latency per hop, and energy per bit transferred. Optimizing each of them makes a chiplet-based architecture behave as if it has one giant pool of ultra-fast memory rather than discrete pockets.
This gives us a way to scale up the available pool of SRAM memory while preserving low latency and performance requirements. But that scales elegantly up to a certain point that falls short of handling the largest reasoning models and the general shift toward significant token consumption.
Rack-scale SRAM with Corsair captures a significant surface area of the space for AI workloads, and disaggregated pipelines with Corsair capture an even larger space. In fact, data released with our partner Gimlet Labs shows that there is as much as a 10x performance boost when deploying Corsair in a heterogeneous pipeline for small-batch inference.
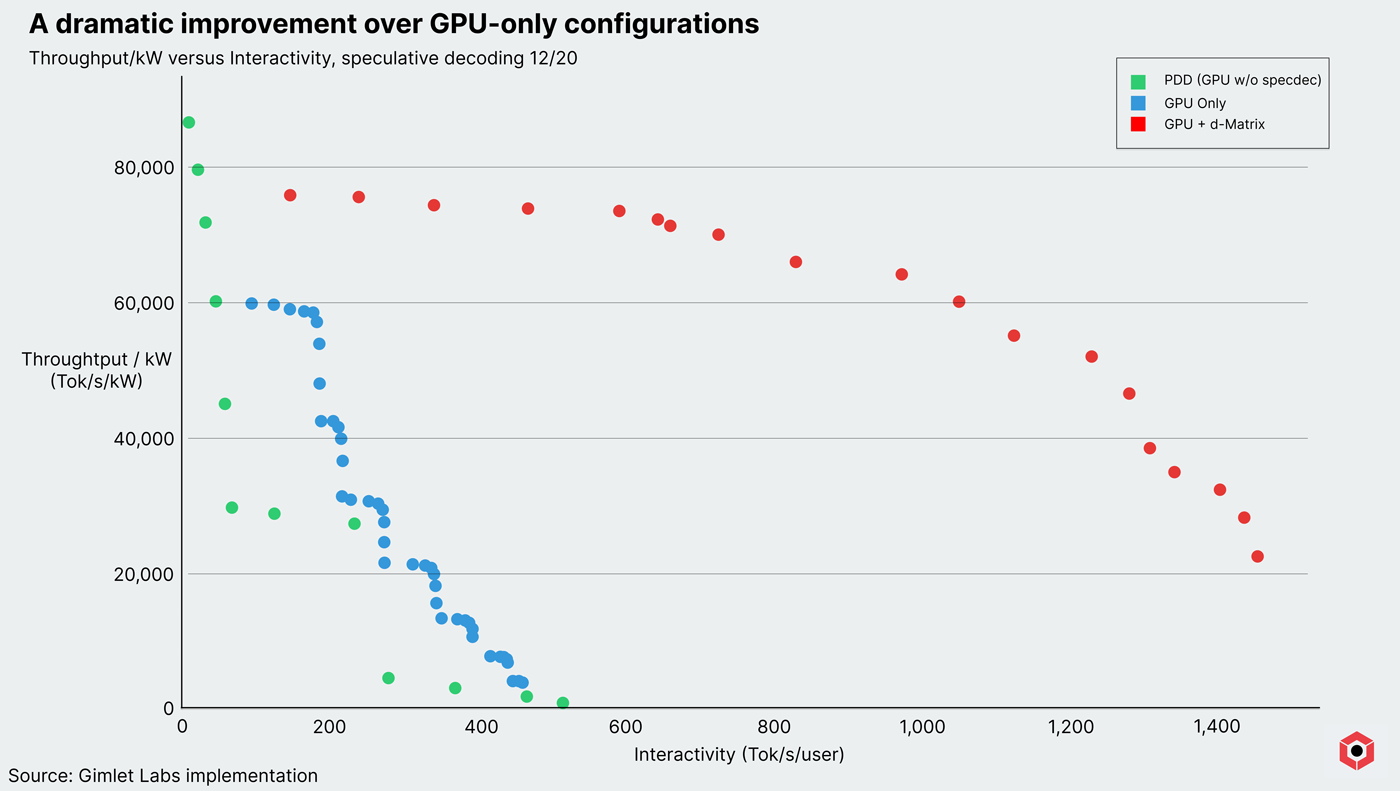
Shifting to 3D stacked DRAM
Modern reasoning models aren’t just larger by virtue of the number of parameters—they also consume substantially more tokens. Even at a smaller scale, reasoning models can consume anywhere significantly more tokens to achieve a result. The total memory footprint is growing on two axes for interactive applications requiring reasoning models.
A stacked 3D DRAM configuration still lives in the die-to-die interconnectivity space, which allows us to target 10x better memory bandwidth and 10x better energy efficiency using 3DIMC over HBM4 configurations.
In addition, our chiplet architecture allows for easier 3D stacking of DRAM, just as it initially allowed for easier scaling of SRAM memory pools. This addresses both capacity and bandwidth limitations constrained by SRAM scaling.
We took passive DRAM we use for capacitors and converted that to an active stack, By doing that we can expose every small bank in the DRAM and directly bring it to the compute engine.
With 3D DRAM, we now have the entire 3D surface area to connect, and the signals can be run at the DRAM base which is a few hundred Mhz. By doing that we can get 20 TB/s bandwidth per stack—10x what HBM4 can achieve—at a power consumption of .3-.4 pJ/bit bit, compared to 3-4 pJ/bit.
3DIMC: Industry’s first 3D DRAM solution for AI inference
We announced 3DIMC, our stacked DRAM solution, at Hot Chips in August 2025. Since then, we’ve accomplished what we hoped—we’ve proven it works. We successfully validated Pavehawk, our test chip for 3D DRAM operates within our performance and power targets, demonstrating that the theory was not only sound, but the attainable path forward to powering next-generation AI inference.
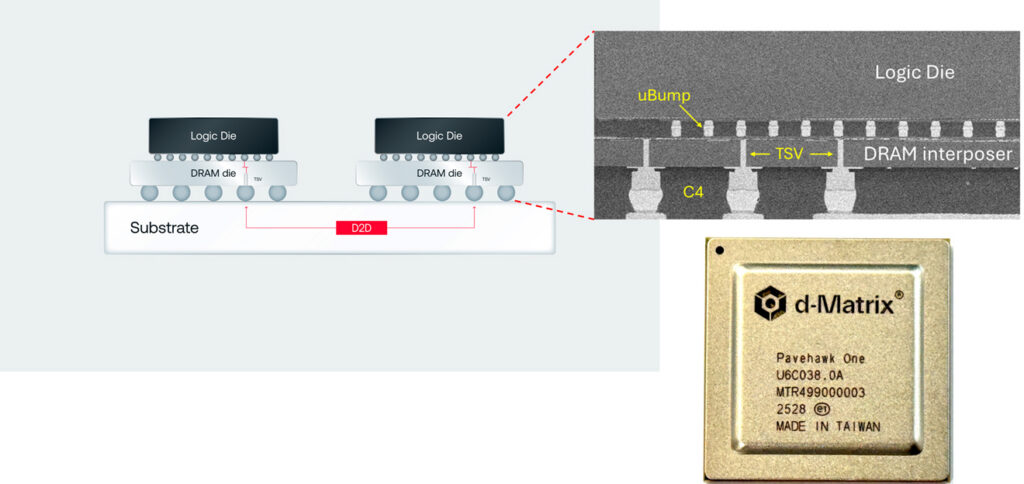
Our stacked DRAM chip, Pavehawk, arrived in our labs in August 2025 and we got to work to test the aggressive targets we set for ourselves. We now have had the opportunity to stress-test the very first iterations of the Pavehawk chips across different voltages and temperature ranges. Thus far we are seeing around 0.4 pJ/bit for the worst case scenarios, and that will decrease further as we complete additional optimizations.
The future of AI inference is 3D stacked memory
The answer obviously doesn’t just lie with throwing an extra layer of DRAM on top of an existing one. Verticality exposes a whole new operating space to grow memory pools and meet the ravenous demand for low-latency, high performance interactive apps.
Corsair was the world’s first accelerator that offered a whopping 2GB of available SRAM per card, with the ability to scale up to 128 GB in a rack. A single server is capable of hosting and running a Llama 3.1 8B model that can handle specific tasks in agent pipelines, and it gracefully scales to larger models in a rack.
Pavehawk is our first crack at the next problem, which will be central to our second-generation accelerator, Raptor. More sophisticated agentic pipelines will require increasingly sophisticated models, and even smaller models are becoming more robust and capable.
Pavehawk not only enables larger models on its own—it dramatically improves disaggregated pipelines in a way far beyond what Corsair offers.
If you’re interested in trying out or purchasing Corsair, you can request early access or contact our sales directly. Our next task is meeting the incredible demand required by emerging AI workloads with high user expectations, and that starts with Pavehawk.