

AI inference pipelines using multiple different kinds of accelerators are providing a more snappy, low-latency experience. Bringing it together with advanced AI deployment techniques is unlocking even more benefits.
Disaggregated pipelines have demonstrated the next biggest opportunity to drastically improve the AI inference experience—both in terms of performance and sustainability. But that isn’t just limited to sticking a whole decode process onto a custom-build accelerator optimized for AI inference decoding.
Instead, custom accelerators can tap into some of the best practices currently used by GPUs—starting with one of the most powerful: speculative decoding.
It’s deconstructing the entire decoding process and finding slots that can be disaggregated themselves into heterogeneous pipelines.
And it turns out that speculative decoding is one of the most powerful ways to drastically reduce latency in AI inference and increase the utilization of already-deployed GPUs—and it works in disaggregated AI inference pipelines right now.
How speculative decoding works
Rather than run an entire inference on a single GPU, speculative decoding splits the task into two interdependent pipelines: the speculator and the verifier.
The speculator runs a smaller, faster, and more efficient model that drafts a sequence of “suggested” tokens in quick succession. Those tokens are then passed to a more powerful model — like one hosted on a GPU with a much larger pool of memory — which verifies them all in a single forward pass.
The actual decode process is typically sequential, which is why memory-optimized accelerators perform well here. Speculative decoding lets larger models do the “checking” in parallel, and then once there’s a mismatch, the speculator takes over again.
The advantage here is two-fold: GPUs get to an optimal balance between batch size and latency along with processing fewer inferences.
More importantly, improving speculator models rapidly improve the performance of the entire pipeline. Disaggregated pipelines can take advantage of the major innovations emerging in smaller models—not just improvements in massive ones.
Rather than reducing the batch size on a GPU and wasting compute to generate a low-latency experience, it reduces the total number of sequential inferences the powerful model handles.
How disaggregation supercharged speculative decoding
Disaggregated computing produced a dramatic improvement to AI inference by splitting up two of the key phases of AI inference —pre-fill and decode—by offering the ability to massively speed up the decoding process. GPUs excel at pre-fill—the “set-up” for AI inference—while memory-optimized accelerators can provide an extremely fast decode process.
As a result, the inference time is drastically cut by reducing the decode process to just milliseconds with significantly more efficient hardware. Disaggregated pipelines can provide much faster experiences, while reducing the overall consumption footprint of an AI inference.
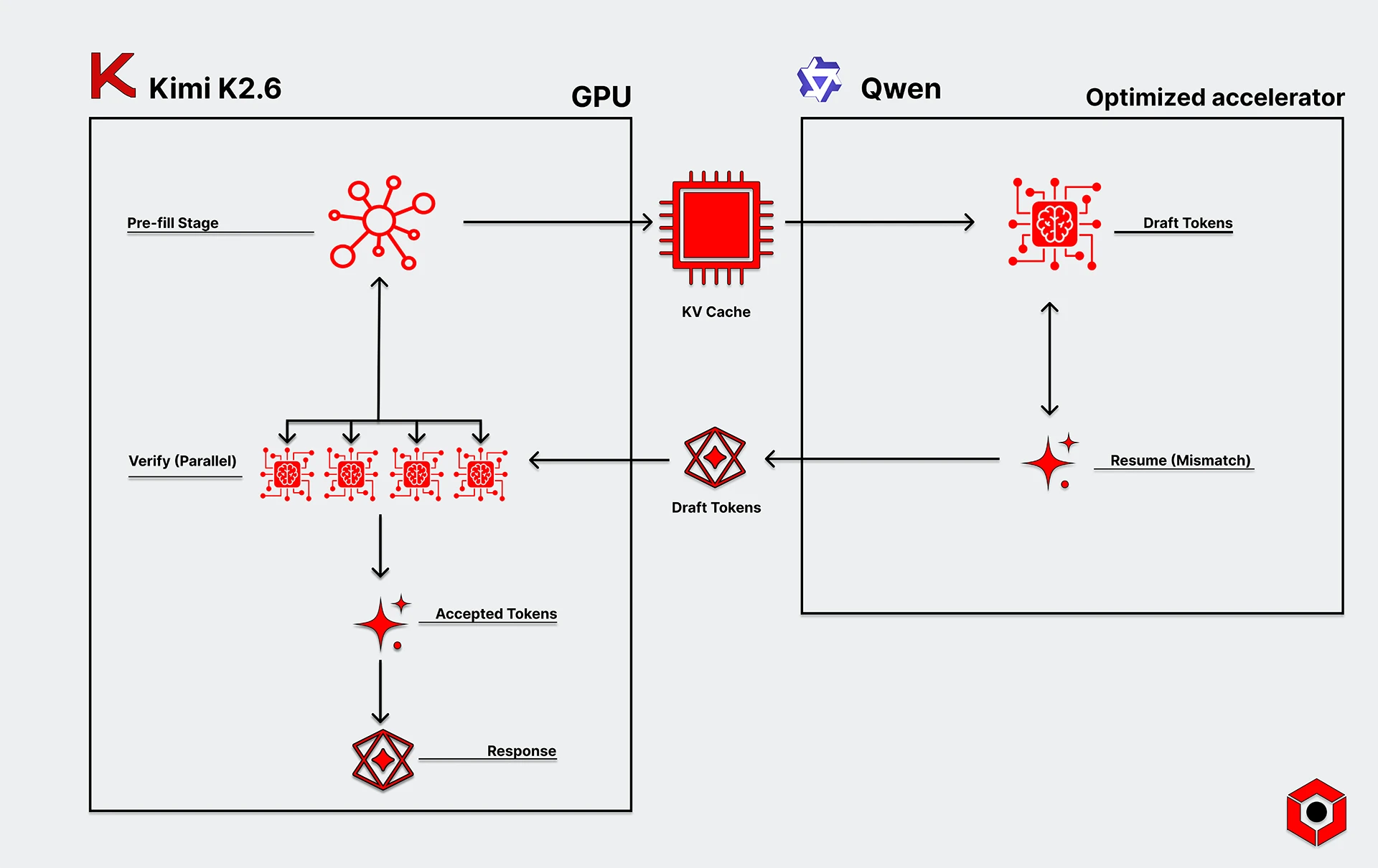
Speculative decoding takes further advantage of that disaggregated approach. Custom, memory-optimized accelerators don’t have to own the entire decode process—but they can still massively accelerate it by running a speculator in an extremely efficient and low-latency fashion.
A memory-optimized accelerator, for example, might host a smaller coding model that’s pretty good, while a GPU stores a much larger and higher quality one (such as the new Kimi K2.6).
Adding speculative decoding to an AI inference pipeline with even a smaller pool of memory still offers significant performance advantages. Scaling up the decoding process to a larger pool of memory-optimized accelerators further supercharges the process by providing better speculator models.
The future is, still, disaggregated
Disaggregated pipelines are only now exposing the underutilized opportunities to produce an extremely low-latency experience—as well as scale it up gracefully.
There are other rooms where memory-optimized accelerators can improve the process even further, such as in an attention feed-forward network—which we will discuss in a future post.
This also comes at a time when AI inference is exploding, exposing a massive compute crunch and leading to harsher usage limits and more downtime. Despite the improvement in model architecture, smaller models will play a critical role in powering next-generation AI inference—both in terms of performance and cost.
And user expectations aren’t even staying stable—they’re drastically rising. Claude Code, Codex, and other agentic workflows have exposed the power of AI models, and everyone wants a piece of it.
The challenge is now making the whole AI inference experience faster and more sustainable. Addressing each optimization opportunity in a disaggregated pipeline is the best pathway to chip away at those limitations piece-by-piece.


