

Time-to-first-token, or TTFT, has generally been one of many key performance indicators for AI-based applications. Consumer-facing chatbots, for example, might need it to be very low, while enterprise cases can tolerate higher degrees of latency.
The emergence of agentic workflows is quickly changing those requirements and upending what determines the success of an AI workload. Latency is now one of the biggest determining factors in a user’s experience.
Agents can individually be responsible for tasks like orchestration, action, summarization, and others. But combining agents together means combining all the latency penalties of each. Minimizing that latency for every step then becomes a key factor of success.
Even “classic” AI-powered applications, like customer service chatbots, are finding the need to deploy agentic workflows rather than a single Q&A experience from a single model. Chatbots now need to be smarter and more personalized, which now can require a multi-step approach.
Successful agentic workflows must complete their entire inference practically instantaneously to move to the final response without destroying a user’s experience. That includes completing the pre-fill stage and generating all tokens required for the next agent. These workflows increasingly necessitate a re-think of classic GPU architecture, which requires a lot of shortcuts to keep latency as low as possible.
But all that hacking naturally carries an upper bound. New techniques come out regularly, but something must eventually give—and send us back to the whiteboard entirely.
What’s changing for user experiences
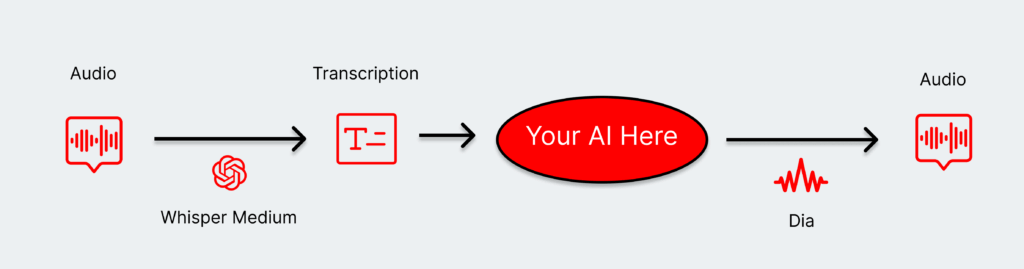
Customer chatbots might have started with a web interface, but that overall scope is expanding. They can provide a better experience through voice-based experiences, for example, by extending that typical chatbot functionality to phone calls or kiosks.
Voice-based workflows could be as short as three to four steps:
- Speech transcription using ASR models like Whisper.
- A RAG lookup for related information.
- A response generated predicated on that RAG lookup.
- An audio response generated and sent to the user.
The key latency requirement for this kind of voice-enabled chatbot is converging to sub-second responses for the entire agentic chain, not just a single agent. Each of those agents has to quickly spin up, pre-fill, and generate a response nearly instantaneously. And that’s one of the most basic workflows you could put together. The chain of agents could quickly sprawl into a larger number of steps, including:
- Data substitution to replace any personally identifiable information and ensure security safeguards.
- Additional RAG lookups beyond just user information, such as relevant internal information (like, say, payment plans).
- Multiple LLM agents chained together when a single LLM isn’t good enough.
- An orchestrator for determining the flow of information and selection of agents across the entire agentic plane.
Each step naturally introduces a latency penalty, and the longer the chains get, the larger the penalty. Yet sub-second latency is still absolutely necessary to power a positive user experience.
“Hacking” latency and the power of disaggregated compute
These extreme latency requirements have forced us to re-think the entire architecture of AI workflows. And there’s another way toward extremely low latency experiences without all the hacking and complexity, through: disaggregated compute.
Like most modern workflows, these new agentic chains are bound to the performance of classic GPU architecture. And generating that level of latency requires an extremely small batch size—even as low as a batch size of one. But capturing that latency then incurs a much larger operational penalty: GPUs, which operate best at higher batch sizes, are nowhere close to max utilization.
Heavy prompt caching is one way of reducing the pre-fill requirements. Introducing an orchestrator, as we talked about above, allows every agent in a flow to activate with the initial response ahead of its turn. Orchestrators can then terminate any agents that aren’t necessary once a prompt comes through, but that still introduces an “always on” agent for every user-initiated request.
A single agentic app can be a multi-stage process that can require a wide variety of model types, such as text generation, ASR, and text-to-speech. Those models all have unique requirements: some are larger and memory bound, while others are more compute bound. A one-size-fits-all approach wastes the opportunity to further optimize those models with different types or hardware accelerators that specialize in the unique circumstances of an agent in a pipeline.
What’s on the horizon
Voice agents are only recently viable, but they represent one step toward something larger: extremely low latency multi-modal agentic flows with even larger models and extremely low latency requirements.
It’s early for voice agents, so there’ll be plenty of user forgiveness at first. Developers may be able to deliver the level of quality users to expect with smaller models. As more companies begin fighting amongst each other, though, user expectations will continue to go up. And it will continue to rise across a whole spectrum of outputs.
- Those same voice agents might need agents that are powered by larger and advanced reasoning models.
- New modalities, like video generation, will require even lower latency to make the generation practically invisible to users.
- Agent chains could get even longer as AI unlocks new workflows and use cases.
This puts existing paradigms on an unsustainable path to growth. It also generates a lot of room for innovation across the board: model efficiency, API refinement, and of course, the actual hardware with mechanisms like disaggregated compute.
Practical voice agents also, unsurprisingly, snuck up on us. These newer use cases will likely do the same, and the best way to create great user experiences is to rethink the entire stack.


