

Just a year ago, the quality of AI models was measured with a mixture of scientific benchmarks, LMArena rankings, and — weirdly, most importantly — vibes.
Agentic networks have changed the equation, bringing the opportunity to optimize applications across multiple modalities with different targeted models. But while you see a long chain of models with their own individual metrics, the user on the other end only sees one thing: did it work, and was it fast enough.
Evaluation, now, is about aligning those two realities. The CEO’s Grafana dashboard consists of KPIs, not performance metrics, that an entire company can understand and rally behind (like a “cost per successful outcome”).
Getting that value right — or getting it in the first place — as a composite of everything under the hood is the difference between deeply understanding a product and just kind of winging it.
The three questions that actually matter
The reality to the end user is that an “agentic pipeline” is just a product, and they don’t care about what’s under the hood. That requires distilling the mechanics of the pipeline into what’s going on in the user’s head:
- Whether it worked in the first place. Did the chain complete without failing, falling back to a human, or producing garbage? This is the flat-out baseline, and it’s a deceptively challenging one when running a multi-step pipeline where each model introduces a new point of failure.
- Whether it did what the user wants. Again, the end user doesn’t see whether all the models fired correctly under the hood and how much work you put into shrinking latency. They see the result on the other end — and it needs to meet their standards.
- Whether it actually followed the rules. Pipelines also need guardrails, compliance requirements, and their own kind of policies like RBAC. An agent that gets the right answer by sifting through a bunch of stuff it’s not supposed to or going off-script isn’t a success — it’s an enormous liability.
It all sounds simple, but measuring them across a pipeline with dozens of models, tool calls, retrievals, fallbacks, escalations, conditions for human intervention, and everything in between is a total mess under the hood.
Two completely different scorecards
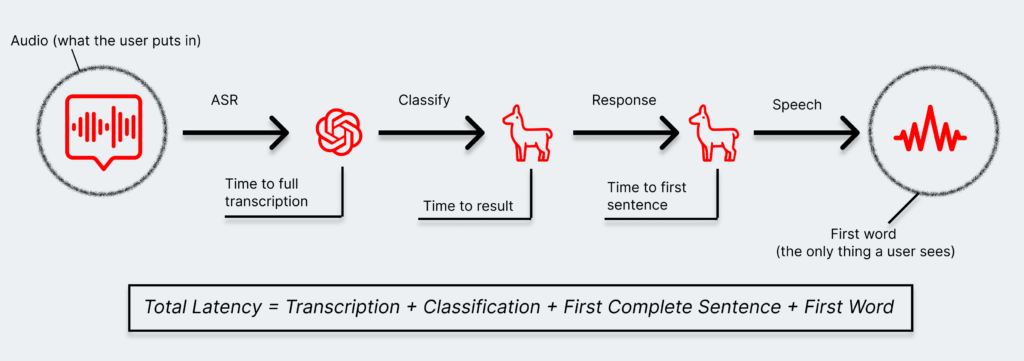
A user talking to a voice agent sees exactly one thing: how quickly the first word comes back, and whether the response was actually helpful. They don’t know or care that there were four models involved, or that one of them had to retry, or that a retrieval step added 200 milliseconds. The experience is singular — it either felt fast and useful, or it didn’t.
The enterprise, on the other hand, needs to see inside every step. Each model in the pipeline comes with its own latency, its own failure rate, its own token consumption, its own cost. Take that same voice pipeline:
- The transcription has to be correct — an inaccurate transcription threatens to derail the entire chain from the very first step. That might even mean calling it multiple times to verify.
- The classification has to be correct, because it narrows the scope of the problem and routes it to a more targeted, faster, and efficient model.
- The response has to actually answer the user’s question. That might involve adding a judge model to evaluate quality — which adds a whole additional step of latency.
- The response also can’t include sensitive information. More complex and ambiguous products like voice-enabled customer service may require additional guardrails on top of that.
- And everything has to be tight and snappy. A model flying off the rails and burning 10,000 tokens instead of 1,000 doesn’t just hurt one interaction — it doesn’t scale.
That’s five steps, each with its own definition of “acceptable,” each with its own way of failing. And the user on the other end just hears a voice that either helped them or didn’t.
You could imagine a metric that reconciles both sides on a Grafana dashboard in front of the company, which could look like something like a cost per successful outcome. It collapses the entire enterprise-side laundry list into a single number that’s accountable to what the user actually experienced.
We’re bulldozing into a situation where p50 performance is almost irrelevant. Outlier and edge cases are the ones that typically define a product’s reputation. A user won’t remember the one question that worked — but they’ll remember when the agent broke down while they were stuck on a train in a tunnel, trying to rebook a flight.
Success is a moving target — but we’ve been here before
Pipelines are only getting longer and more complex. Each new capability, like tool use, retrieval, and multi-turn reasoning, adds value and adds a potential point of failure. That collection of metrics can seem like it’s growing significantly faster than we can keep up with right now.
However, SaaS products went from struggling to reconcile dozens of new variables to settling on scalable, actionable, cross-organization metrics like churn, CAC, NPS, and conversion rates. Consumer-focused products settled on engagement metrics like interactions and time-on-site. None of those were necessarily obvious from the start, and instead came from learnings (and a lot of user complaints) with the MVP out in the wild.
Agentic networks are at that exact same stage. Enterprises are going to figure out over time how that naturally combines into something intuitive and coherent and a (mostly) direct indicator of success. But the vibes are there—it’s just a new generation of vibes that has to work until then.


