

Agentic AI tools like Claude Code, Codex, and Cursor have fundamentally changed the way we approach software engineering. Rather than spending days or weeks on developing and managing software, the whole process can happen in a few hours — and by a mostly-autonomous agent while you’re working on something else (or sleeping).
These tools are only becoming more popular and more powerful. But demand is exploding at the same time GPUs are increasingly hitting walls in both availability and performance.
Heterogeneous pipelines attack both of those bottlenecks, providing substantially improved latency and enabling GPUs to focus on where they shine. Disaggregated pipelines that introduce techniques like speculative decoding to further improve latency and efficiency and scale up to more complicated workloads.
As a result, these pipelines offer a way to relieve the explosive strain that stands to degrade or make unavailable these incredibly powerful coding tools.
The GPU wall in code generation
Even before the emergence of AI agents, code generation was well on its way to becoming a wholly different experience. AI models from the get-go could generate large swaths of code on their own, as well as drastically augment the engineering workflow with rapid inline suggestions and completions.
That changed late last year when AI models within agentic workflows— particularly Claude Opus 4.5—became extraordinarily more capable and able to generate high-quality results autonomously. The scale and demand for high-performance coding agents are now exploding as a result.
Code generation, like many other applications, has always had to strike a delicate balance between latency and compute. GPUs excel at the prefill process by absorbing an entire codebase or project requirements and building out a KV cache necessary for decode. But it quickly runs into latency walls once they begin generating results due to constant back-and-forth trips between HBM.
AI agents have only exacerbated this, with programming becoming a multi-step process that runs nearly completely in the background for hours at a time. That’s led to degraded performance, higher latency, increasingly aggressive rate limits, routine downtime, and ballooning operational costs. GPU-only systems are clearly not the path forward to managing the extraordinary demand for agentic coding tools.
How heterogeneous pipelines break through the GPU wall
Generating code increasingly involves steps that demand a different approach than GPUs alone. The dearth of overall compute for inference has made efficiency a substantially higher priority. And user expectations for latency are rapidly growing for a snappier experience with high quality results—particularly as AI coding agents begin to take over whole workflows in the software engineering role.
Agentic pipelines using multiple types of hardware in a heterogeneous pipeline with different memory architectures helps resolve both. Simpler tasks that smaller models can handle can sit on memory-optimized accelerators—like those taking advantage of SRAM-approaches—and operate with significantly lower latency than GPUs.
Some tasks—like complete refactors, complex functions, architectural decisions—are extraordinarily complex and need the firepower of a trillion-plus parameter model. But many are simple: searching codebases, identifying diffs, catching straightforward bugs, or generating inline completions.
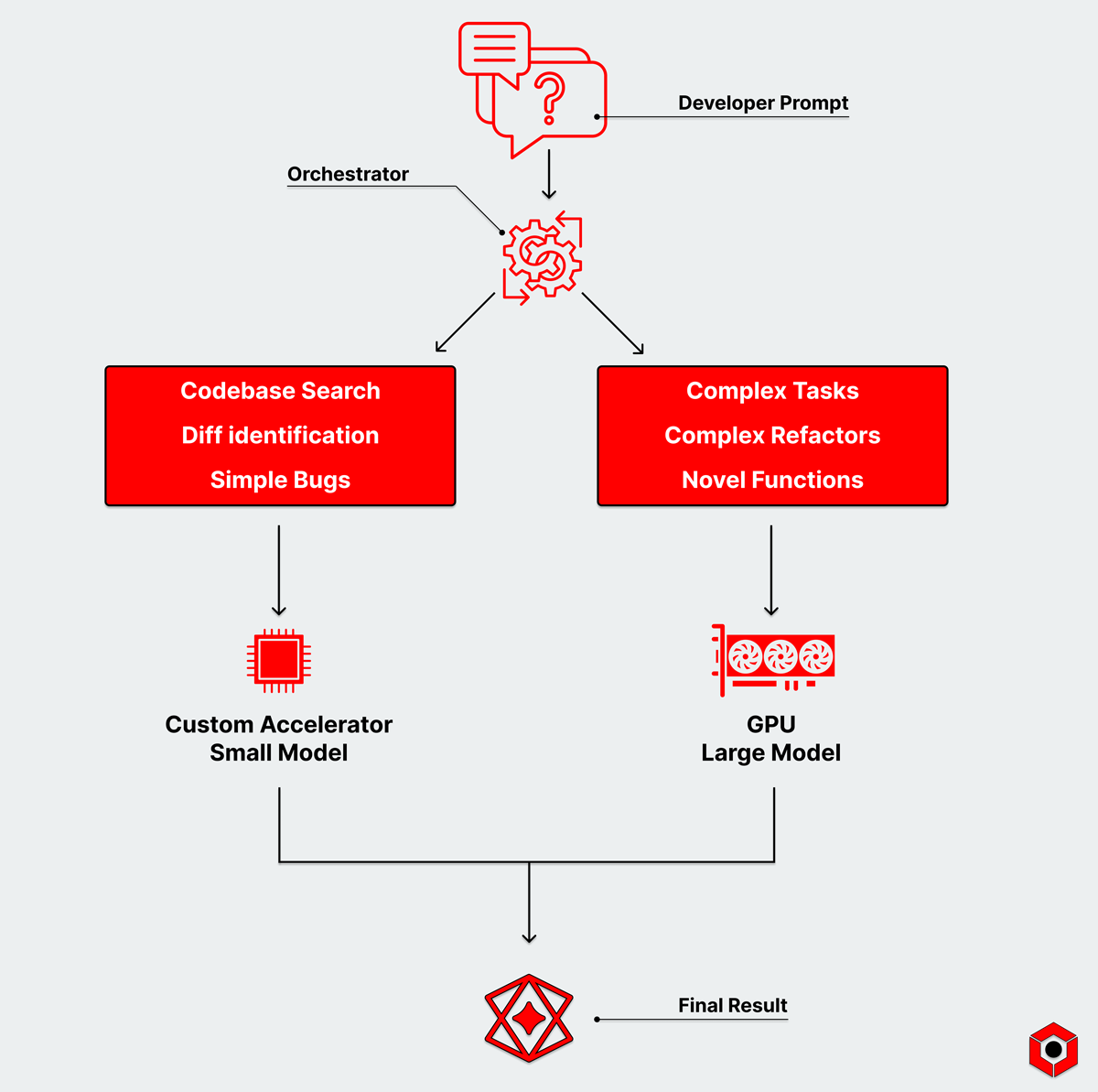
Each of those tasks doesn’t need the same monolithic model that can solve every problem. Smaller models are more powerful today and can tackle the simple stuff while massively reducing overall latency and energy demands.
These newer, more advanced pipelines divvy tasks up across a wider portfolio of models within a multi-step agentic flow. Even the models themselves can run on different types of hardware, such as handling the entire decode process of small- to mid-sized models, or improve the elements of the decode process individually.
Disaggregated AI inference supercharges speculative decoding in programming
Even the most complex tasks that might be better suited to large models don’t have to rely entirely on power- and compute-hungry models (and, as a result, GPUs).
In a disaggregated pipeline, custom accelerators running smaller models can speed up the overall inference process through speculative decoding. Inference-optimized custom accelerators rapidly generate draft tokens while a GPU with a more powerful model verifies the best results in parallel.
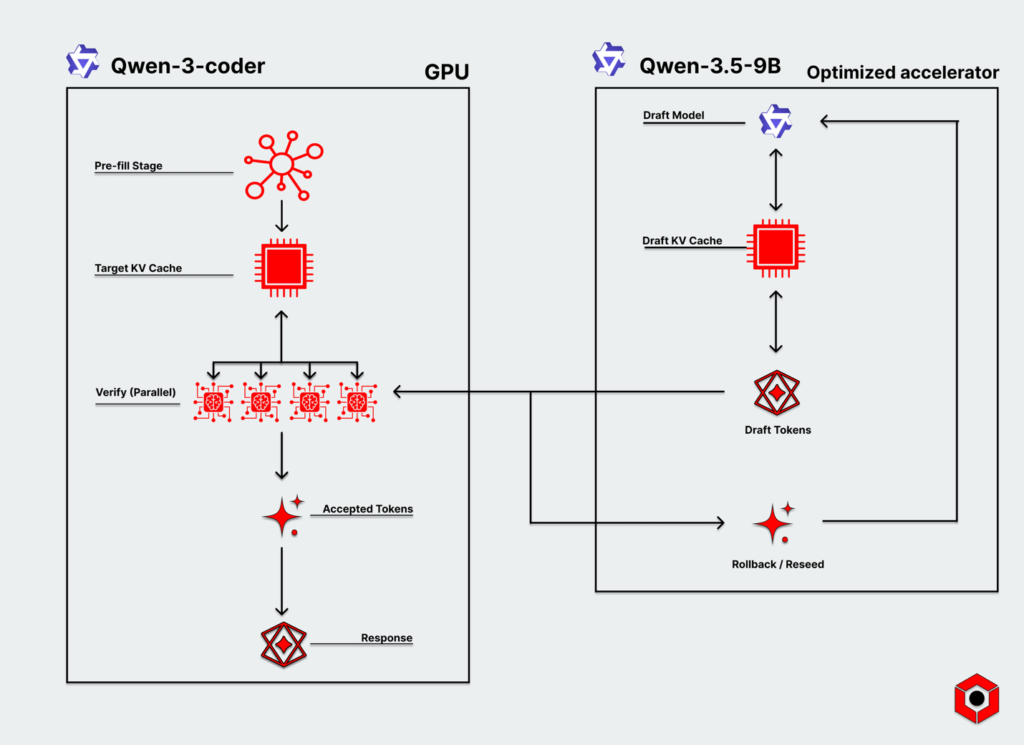
A speculator model in code generation can rapidly throw out a high volume of proposals finely tuned to a developer’s specific requirements. That could include tuning with a company’s codebase. But it could also include tuning based on an individual developer’s own preferences and style, from variable names to the structure of functions.
Smaller speculator models are also getting more powerful and efficient, which directly improves the quality of proposed tokens and the efficiency of the entire pipeline. And enterprises can deploy speculative decoding in disaggregated inference pipelines today.
Heterogeneous (and disaggregated) AI inference pipelines are the future of AI coding
Agentic coding has solidified itself as one of the most powerful use cases for AI models. Enterprises can supercharge developer productivity and dramatically lower costs, and even solo developers can produce prototypes or entire applications with a good set of instructions.
That demand puts even more strain on existing compute resources, leading to slower and less-than-optimal experiences. Today, enterprises might tolerate an AI agent running off and working for a few hours. In the future, competition may be fierce enough that the acceptable time window shrinks dramatically.
Heterogeneous pipelines by themselves massively improve the process of AI inference. Implementing disaggregated pipelines—including architectural optimizations like speculative decoding— immediately relieves that strain as well as delivering an even lower-latency experience than GPU-only inference.
The (arguably) most important AI use case available today needs infrastructure that can actually keep up with user demands from it. And implementing heterogeneous and disaggregated pipelines is an immediate pathway to scaling gracefully to the exploding demand for it.


