

In the early days of transformers-based AI workloads, generation speed wasn’t that big of an issue. Users generally tolerated slower inference due to novelty, and serious use cases outside of code generation hadn’t emerged.
That dynamic has effectively flipped today. GPUs, even with significant optimizations and runtime tricks, in a best-case can operate in the hundreds of tokens per second and take a considerable amount of time to “warm up” and generate the first token. But defining success within an organization increasingly looks less like an ELO score and more like a classic SaaS KPI like churn, bounce rate, or engagement.
We have to optimize all the way down to the accelerator itself and move beyond a homogenous accelerator system to deliver on those metrics that classically define a user experience. Agent-based workflows make this even more critical because the additional complexity includes even more potential negative impacts for a user’s experience. Low latency will be a critical factor of success going forward.
We need to build new systems that utilize the best hardware for any given step, and next-generation inference-optimized hardware is increasingly making that possible.
The two phases of AI inference (and what GPUs do best)
GPUs are a kind of Swiss-army knife but are no longer an end-all be-all when it comes to AI inference. Deploying custom inference-optimized accelerators leads to a significantly better user experience because of the different dynamics of managing memory. Those dynamics are the most apparent when looking at the two key phases of AI inference:
- During pre-fill, an accelerator is populating a full set of data needed to generate the actual response for an end user called the KV cache. Accelerators can process all of these simultaneously, fully populating the KV cache.
- During decode, the accelerator is actually generating the next token in the sequence and then updating the KV cache for the token after it. Accelerators, however, have to generate tokens one-by-one and update the KV cache each time.
A high-performance pre-fill is effectively governed by how fast accelerators can compute each step (which we’ll call compute bound). There are fewer trips to and from memory because no one step for generating the elements of the KV cache is dependent on another, and all the results are collected at the end. The accelerator with the most powerful raw compute makes sense during pre-fill.
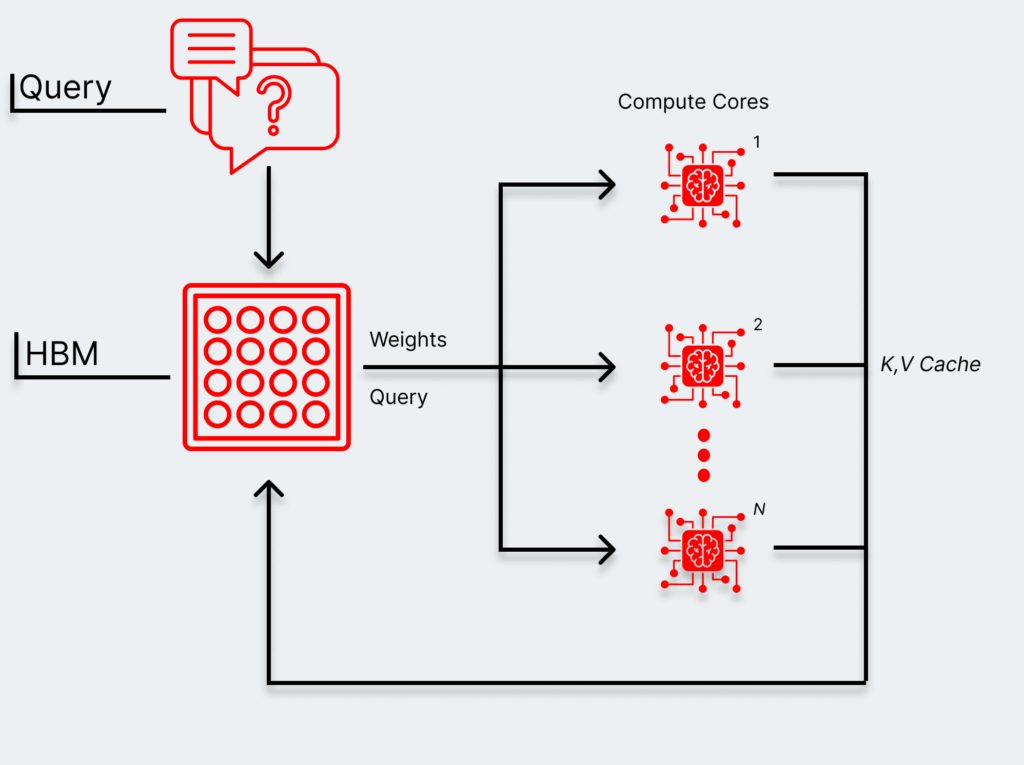
During decode, however, each new token is dependent on information from the prior one. There isn’t enough on-chip memory in GPUs to store all previous token data, forcing it to pull from HBM. Data has to move rapidly between memory and the compute engine to generate each token, making the speed of the response governed by the speed at which those trips to and from memory happen (which we’ll call memory bound). Extremely fast compute is still important, but it’s only half of the equation.
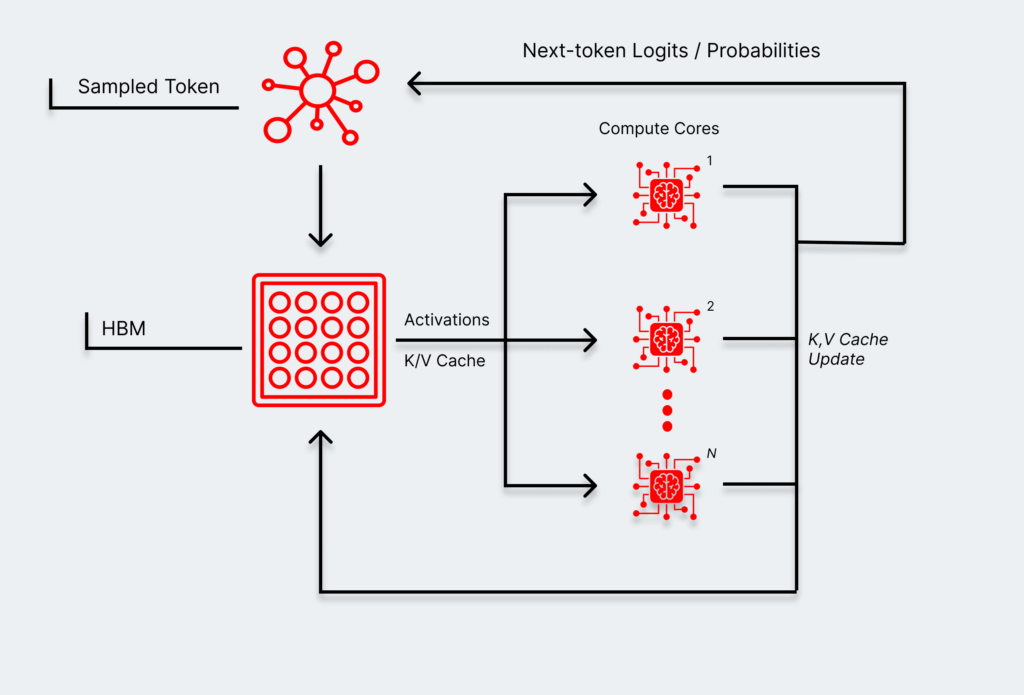
That change introduces the core problem with GPU-only pipeline: you’re always compromising in some way. Lower latency means leaving compute on the table, while higher throughput incurs latency penalties.
Both phases involve the typical mucking around in standard AI processes like managing embeddings, attention, and system software. But that one extra trip to and from HBM during decode makes it a dramatically different architectural problem. That happens for every model in an agentic chain, where every one of those trips adds up.
For example, let’s consider a voice-enabled application (which fits neatly into a customer service experience). Using a GPU-only pipeline simplifies things at the cost of accruing a constant stream of micro-penalties that add up to a negative user experience.
In a non-disaggregated world, a basic two-step agentic chain might look a little like this:
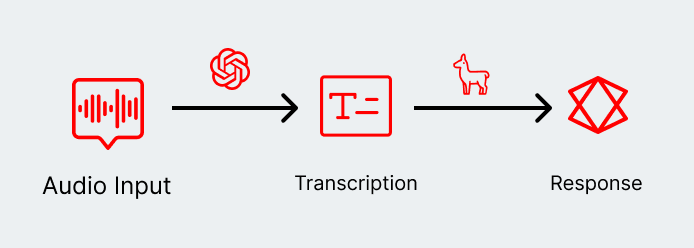
Even a two-step agentic chain, though, is missing a critical architectural decision that can lead to significant performance improvements—and a better user experience. Instead, we can integrate custom accelerators that perform extremely well in either phase. Memory-optimized accelerators can speed up decode, while compute-optimized accelerators can speed up the pre-fill. And modern frameworks make it easier to enable both accelerators in the same pipeline.
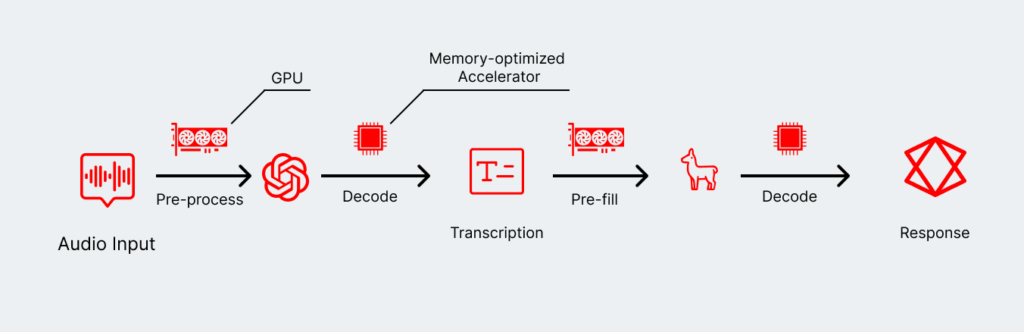
Why optimize the hardware layer
The lower tolerance users have for either high latency or low performance (or both) is pushing that decode-versus-pre-fill challenge even further. Choosing between a homogenous inference pipeline and a heterogeneous one is now a critical strategic decision to keep up with competition.
That decision is a critical one because AI inference landscape has changed significantly since the launch of ChatGPT:
- The level of competition among top model providers—including reasoning models—has effectively killed the tolerance for poor performance and latency.
- A handful of high-value AI workloads are emerging that are powered by agentic networks that go beyond code generation, and many of these are set up to be multimodal.
- High-quality responses may demand reasoning-based models that chew up hundreds—or even thousands—of tokens upfront before a response is even generated.
There’s a laundry list of ways to optimize a single AI inference, ranging from including more relevant context to modifying the kind of attention a model deploys. Hardware exists as one of many of those options, but it’s also increasingly one of the most important.
But increasingly software and frameworks (such as Anyscale’s Ray) are leaning heavily into heterogeneous compute to keep up with the runaway user demand for AI inference.
You could use a single accelerator for everything, whether that’s a GPU or otherwise. But competitors might invest in heterogeneous pipelines and end up with a better user experience.
The capacity to train and run these high-performance models has to grow to adapt to the enormous scale of user demand. AI is as much an infrastructure problem as it is a raw intelligence problem. And the pathway to the next generation of AI-powered applications runs through innovation at the infrastructure layer itself, which looks like a heterogeneous pipeline stitched together, under the hood and hidden from users, that delivers high-quality user experiences.


