

GPU + Corsair: harnessing the power of heterogenous disaggregated compute
SRAM-based approaches have shown, time and again, that they are the unlock for the ravenous demand for AI-powered applications today. But what comes after SRAM, even at scale?
The next evolution in a memory-centric disaggregated pipeline is more memory—but vertical. More specifically, it’s creating a stacked DRAM solution that order of magnitude better bandwidth and power-efficiency than typical DRAM with HBM architecture. 3D DRAM dramatically increases the memory pool available while meeting the demands for highly interactive, low-latency AI applications.
We’ve been building a solution for that, which is now in our labs—and it’s working. And like our original approach to scaled SRAM, it just reinforces the memory-centric demands for future AI workloads. It elegantly meets the demand for latency and performance requirements while enabling significantly larger models and longer context windows.
The AI landscape is innovating at an unprecedented pace. That means we have to keep up with it with next-generation hardware approaches to keep up with it. The current of AI inference will be built on scaled SRAM architecture. The next will be built on a stacked DRAM solution.
The power of disaggregated pipelines with SRAM
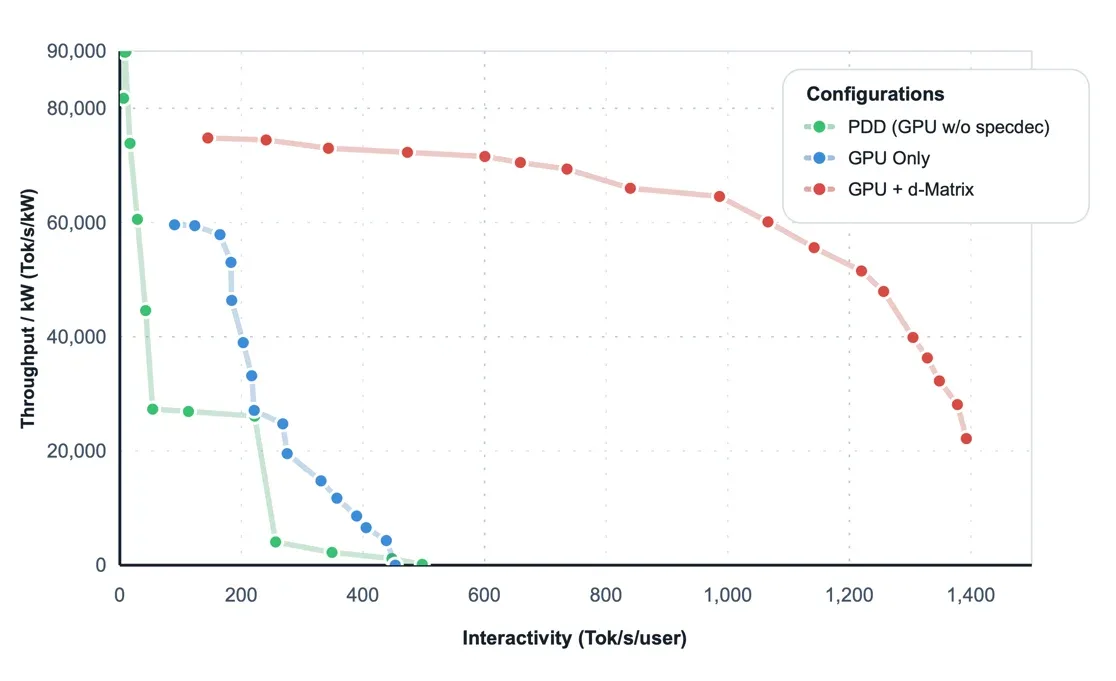
Disaggregated pipelines—where different kinds of hardware are integrated at different points of an inference pipelines—are quickly becoming the best pathway forward to scalable, low-latency inference.
We're partnering with Gimlet Labs to deliver low-latency, high-performance AI inference in disaggregated pipelines. That disaggregated solution offers a 10x performance boost compared to standard GPU-only pipelines with speculative decoding.
That performance is going to be critical not only to meet extreme product quality demands, but to also meet the rapidly scaling user base for those AI workloads. Applications that immediately grow from a few thousand to millions will be facing extreme performance bottlenecks—and disaggregated solutions offer an immediate solution.
Interested in more from d-Matrix?
Get the latest d-Matrix updates to your inbox. Sign up below:

Dive deeper into 3DIMC
We've put together a video that goes into further detail about the performance of 3DIMC we're seeing, as well as what we hope to achieve with it.

From theory to hardware
Our stacked DRAM solution, 3DIMC, isn’t just a theory on a white paper any more.
We successfully validated that Pavehawk, our test chip for 3D DRAM, operates within our performance and power targets, demonstrating that the theory was not only sound, but the attainable path forward to powering next-generation AI inference.
With 3D DRAM, we now have the entire 3D surface area to connect, with 100x vertical connections direct to compute relative to HBM4. By doing that we can get 20 TB/s bandwidth per stack—10x what HBM4 can achieve—at a power consumption of .3-.4 pJ/bit, compared to 3-4 pJ/bit.