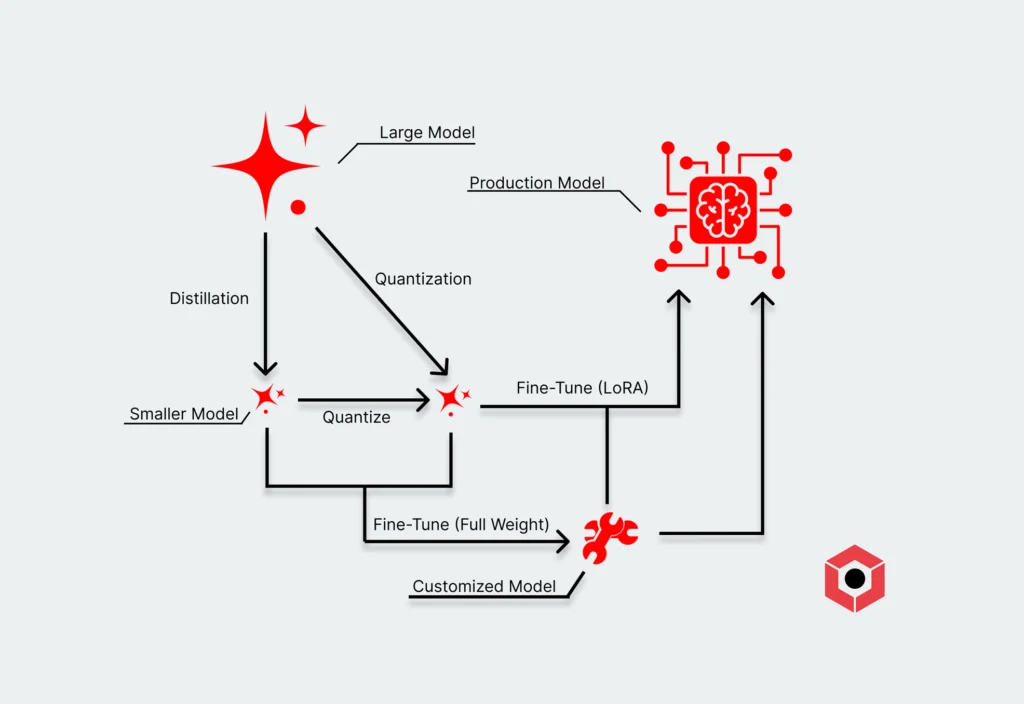
Blazing the Trail Toward More Scalable, Affordable AI with 3DIMC
August 25, 2025
AI adoption is accelerating at an unprecedented pace, but the economics of running AI models are becoming unsustainable. And the cracks are beginning to show. As more people rush to… Read More