
We’ve become accustomed to a brand new model coming out every few weeks that one-ups the last one at this point.
Developers don’t sit with just a single model—in fact, most we talk to just want to switch to whatever the newest one is available. If innovation in AI is as simple as swapping in the newest model, what else is there to improve to give one company a competitive advantage over another?
But that isn’t the only place to create the best-possible AI workflow or product. We’ve talked before about optimizing prompt tuning and RAG setups—but that’s just the surface. There’s a whole layer cake under that to improve performance, lower cost, and build the best (and scalable) user experience.
Today we want to dig into a few of those other layers (with a quick recap of the top). Of course, AI workloads are constantly changing and new techniques come out. But we can try to slice it up into several different spots:
- The application layer where developers are crafting the best experiences with the infrastructure they have and focus on context engineering.
- The model layer where it isn’t just about the best full-precision model coming in, and there are extra steps like distillation, extending context windows, quantization, and others.
- The infrastructure layer where we can look at techniques like disaggregated distributed inference, enabling new architectures at the hardware layer.
- The system software layer where we can create compilers and use a variety of frameworks and orchestration layers, such as JAX or Ray.
- The hardware layer where you pick the best accelerator for the right job.
In most cases, developers are going to focus on higher-level layers because it offers enormous gains without having to deal with complexity of lower layers. But additional optimization goes from a nice to have to a necessity if you’re talking about maximizing and scaling performance when dealing with a dozen competitors. It’s also important when running a product that has multiple customer tiers.
Classic cloud computing workloads have always been optimization problems, trying to provide the best user experience while trying to hit a tiny bullseye on performance and cost. Fortunately, we have now decades of experience in doing that with classic cloud computing.
AI workloads might carry some similarities, but there are whole unique sets of systems to optimize and each of those layers. The ideal workflow is one that is dynamic, adjusting to factors like volume, customer type, time of day, or utilization. And it adjusts to optimize for your highest-valued customers while still providing good experiences for other tiers.
There are the table stakes for any cloud-based application, like load balancing, high availability, fallbacks, and elasticity. But as we can see, there’s a whole additional class of technical factors to consider.
As we’re still early in the AI development cycle, not many developers will have to worry about much complexity and tuning just yet. But the industry is maturing at an incredible rate. Each layer is going to become a battleground at some point as AI workloads become more sophisticated and high-value use cases coalesce beyond code completion—like agentic workflows.
It makes sense to get a head start with all this if you’re serious about building AI tooling that becomes an integral part of a product or workflow.
Customizing the application layer leads to more immediate improvements
The simplest application you can vibe code in an hour is probably a chatbot powered by Nvidia GPUs—or some endpoint provider also using Nvidia GPUs like Baseten, Fireworks, or Together AI. Many organizations have made it trivial to get workloads immediately running on GPUs. And it all works pretty well already!
But if everyone works at that very surface level, every chatbot is practically the same. And while it might offer your customers a slightly better experience, it doesn’t really create the kind of competitive advantage that AI can provide.
That, instead, starts with building out a whole stack at the application layer to augment AI tools and products. This type of tuning and customization also has a name: context engineering.
It’s pretty easy to build a RAG-supported chatbot, especially if it’s just powered by a model endpoint. But it’s where the real differentiation between products and companies begins. No one else has the unique data you have. (At least, hopefully they don’t.)
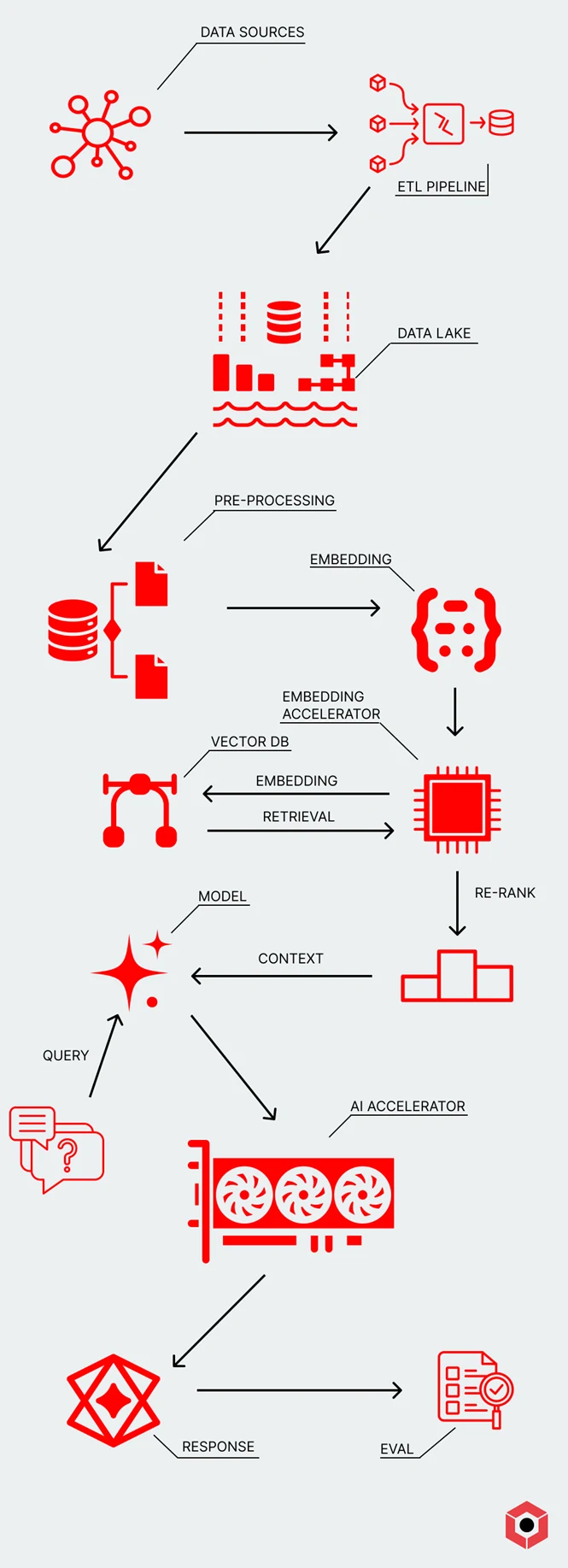
Context engineering involves creating a more advanced workflow beyond simply prompt-tuning. You’d select a set of models, including embeddings and re-ranking, to go with your initial prompt. You’d also put together a pipeline to push the correct data into that workflow.
We’ve gone into additional depth around context engineering in a separate blog post, but in short, it includes:
- Integrating existing data engineering pipelines to get pre-processed data for embeddings
- Managing embedding and retrieval systems to optimize the data going into a given prompt.
- Implementing advanced search techniques like graph search on top of a RAG workflow to deliver better results. With a proper re-rank, an inference can provide a set of starting points in a graph that make traversal more efficient.
- Writing effective prompts that include the correct structure of the intended output, examples, and any other information to ensure a high-quality response.
- Evaluating the results to create a feedback loop and ensure high-quality prompt tuning.
Any company building a workflow that includes a conversational agent, enterprise search, or any other application that needs data to be effective is going to have a RAG system set up. As a result, solid context engineering and data pipelines are table stakes at this point. And there are already tons of options out there—including open source—to handle all the steps of context engineering.
While a RAG-based application backed by proprietary data creates a competitive advantage, your peers might also have a similar set of data to support their RAG workloads. That’s why we’re entering a phase where AI workloads are increasing in complexity, starting with work at the model layer to boost the quality and performance of those AI applications.
How customizing the model itself kicks off a much more advanced AI workflow
Building a true competitive advantage is predicated on having great data in the first place. But it can also go beyond just augmenting prompts: you can optimize and augment the models themselves with well-developed techniques. This unlocks a new level of performance in AI workloads as it sheds some of the rigidity that classic RAG-based applications have.
For example, models may be adjusted to be task-specific, skipping several steps that require aggressive prompt tuning and giving it a more flexible way to approach those tasks. This is effectively a precursor to agentic networks: rather than relying on one model to handle many tasks with some error rate, a workload can fly through smaller task-oriented models that run significantly faster with higher guarantees of accuracy.
Imagine you are trying to process customer service tickets, knowing when to escalate them or what information to grab to answer the questions. You can use a fine-tuned model on a class of existing tickets to see whether it needs to be escalated to a customer service agent right away. Then, as the conversation progresses, an agentic network can “pass” the task on to the next model that’s specialized in that type of customer ticket.
These smaller models offer significantly better latency and throughput, leading to a much smoother user experience. And if too many passes between models occur, it sends it to a customer service agent anyway.
We can dig into a few examples of where you can create these task-specific models that will improve your workload’s performance (and a few more generalized ones that are augmented by your data):
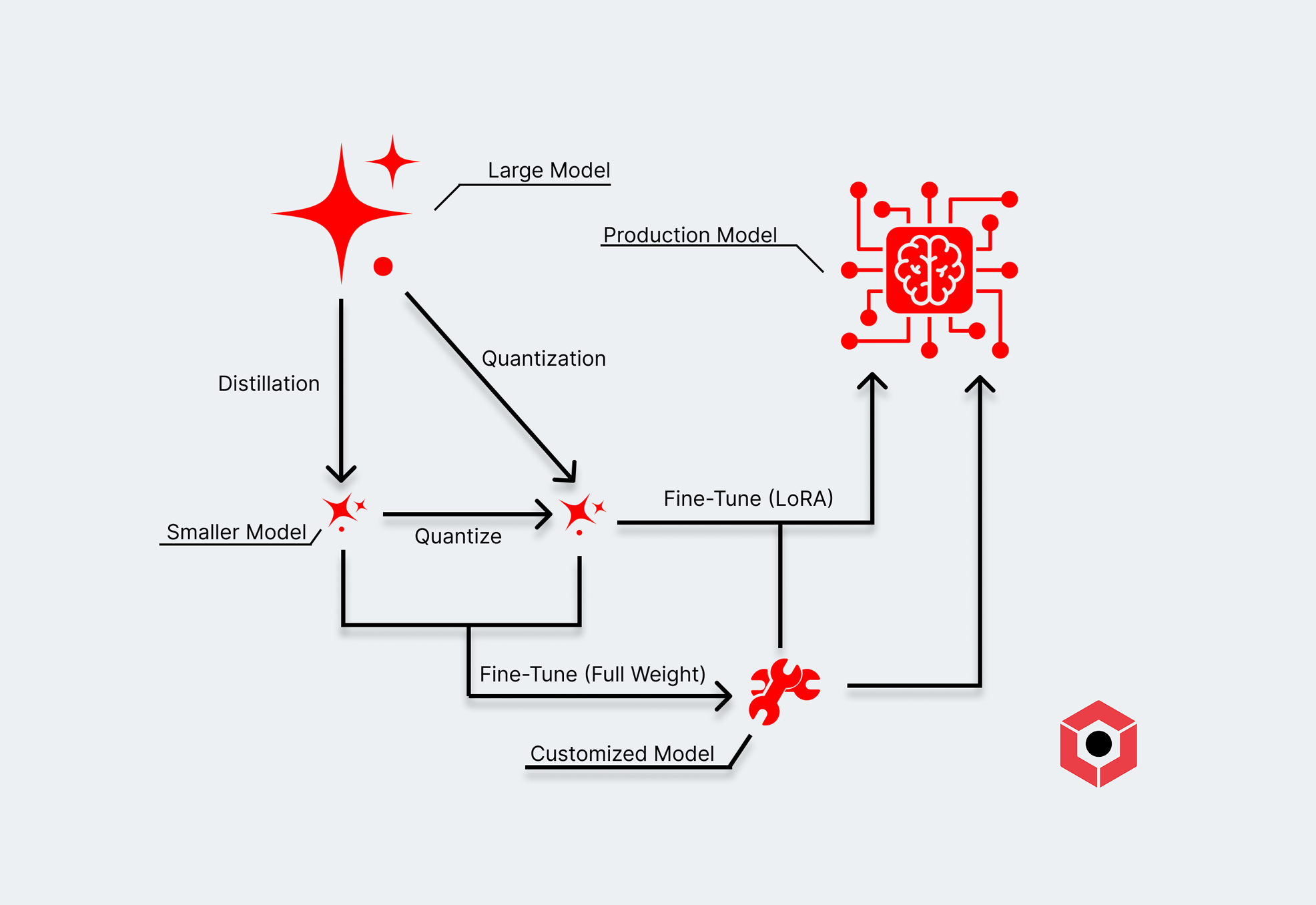
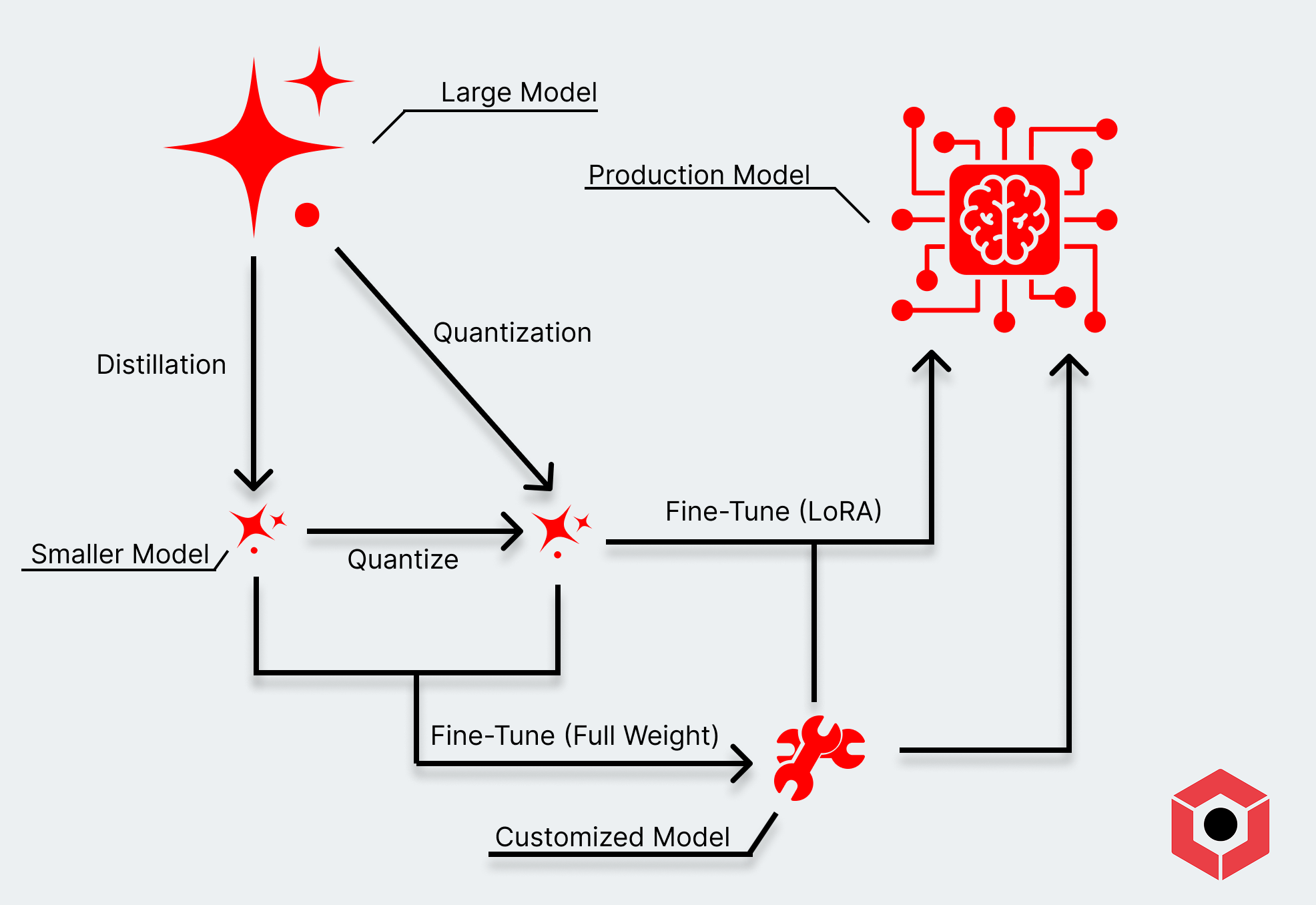
- Fine-tuning can involve fully updating the weights of an existing model (like open weight models pulled from Hugging Face) with more task-specific data.
- LoRA adaptors offer another way to fine-tune, creating additional “layers” that sit on top of existing weights of a pre-trained model. Training a LoRA is a much more approachable (and cheaper) way to approach fine-tuning.
- Distillation takes advantage of the extremely potent models available as open weights, training a smaller model with a more advanced one (like DeepSeek R1 or Qwen3). This gives developers a way to get a model that both behaves more in the way they intend and operates with a lower overall footprint.
- Quantization compresses an existing model into a format that can run with lower amounts of memory and compute while trying to maintain the quality of its higher-precision model. You’ve probably seen this in the form of an “fp8,” “int8,” or “Q_n” nomenclature, and some of these maintain performance relatively well.
- Adding function calling capabilities to enhance the toolkit each of your customized models has available.
- Customization beyond LLMs like fine-tuning embedding models to improve the quality of retrieval systems or applying re-ranking models.
All of these techniques are more advanced than building a RAG-based application. Fine-tuning a model with proprietary data require the extra compute upfront. Developers looking for much more advanced optimization techniques, though, can squeeze even more performance out of smaller computational and memory footprints.
Each of these techniques could go into an AI workload in some form to ensure that you’re still able to accomplish that above-average complex task. And if you’re expecting to use the model over and over again, you get more benefit of the upfront work. Expanding the task list could involve just creating additional adapters for the same model, rather than a complete fine-tune.
Custom models offer another immediate competitive advantage, but there are even deeper layers. Data is a moat, but highly optimized deployment architecture is a way to flex the strength of your engineering skills and highlight another moat: your team.
Get the latest d-Matrix updates to your inbox. Sign up below:
Adjusting the model architecture itself offers another boost
There are even further ways at the model layer to improve efficiency and performance beyond customizing the model. Models are increasingly moving towards a Mixture of Experts approach, where a subset of parameters of a large model are selected to deliver a response. This reduces the total number of parameters activated during an individual response.
But they—and dense models—still need to meet a level of performance to deliver an improved user experience. To that extent, developers can modify the model execution in a handful of ways.
- Sparse attention to reduce the overall compute footprint of models. Rather than run full attention—comparing against every word in some input/response—you apply a sliding window that limits the number of elements that one token is compared to.
- Extending context length with techniques like RoPE (rotary positional embeddings) and YaRN (yet-another RoPE encoder). These allow you to extend context length without needing additional training for the model. You can take advantage of models you’ve already customized and make them work in specific cases that require higher context lengths.
- Group query attention assigns a set of layers in a model inference its own KV cache—essentially a self-updating data store to provide a result for either the next layer or the token output. For example, in a model with 32 attention heads, heads 1 through 8 may get a single KV cache, while heads 9 through 16 get another.
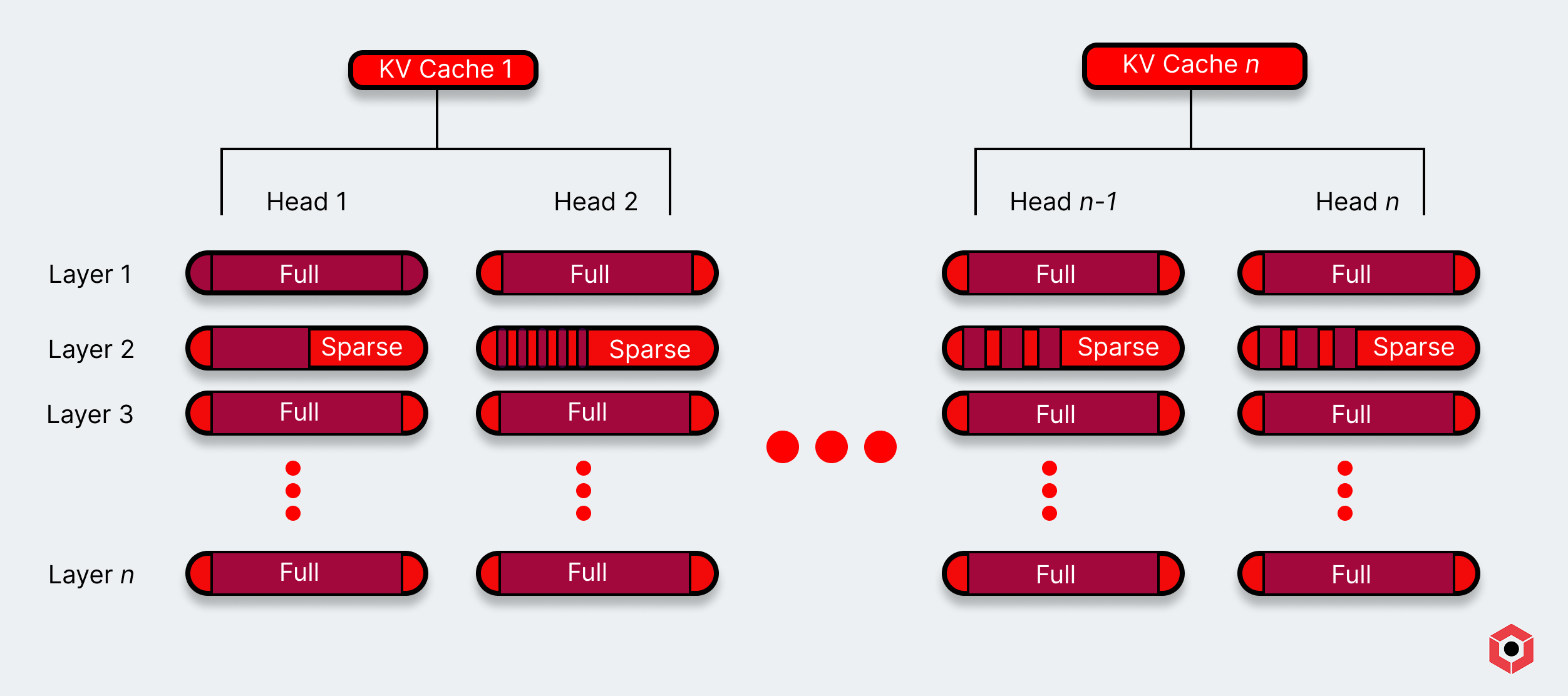
You can even alter the attention mechanisms during a model inference. For example, OpenAI’s newest open source model alternates between full attention and sparse attention (using a sliding window) during inference.
This is especially important for models that have more intense inference performance requirements, such as reasoning models that require extensive “thinking” before delivering a final response. In that case, the number of tokens generated quickly balloons, and there’s a need to save some space.
How building high-quality infrastructure under the models boosts efficiency and performance
If your agentic networks are starting to get significantly more complex and your application is taking off, it’s time to go even deeper by combining a lot of the concepts to make sure everything is running smoothly and hits performance requirements.
Infrastructure modification is all about creating a custom AI pipeline—and not just augmenting models and prompts. You’re looking closely at what defines the success of a workload for your application specifically and modifying the infrastructure in addition to models to achieve it. You might have performance and uptime KPIs to hit. Or it could include “softer” metrics like quality of response, which requires a constant feedback loop with the end-user experience to feed back into the application.
The infrastructure layer offers another opportunity to improve an application. Technically any number of companies or developers can use the same architecture. But It requires a deep understanding of the application or workload and how to steer it toward success. That, in the end, requires a strong team.
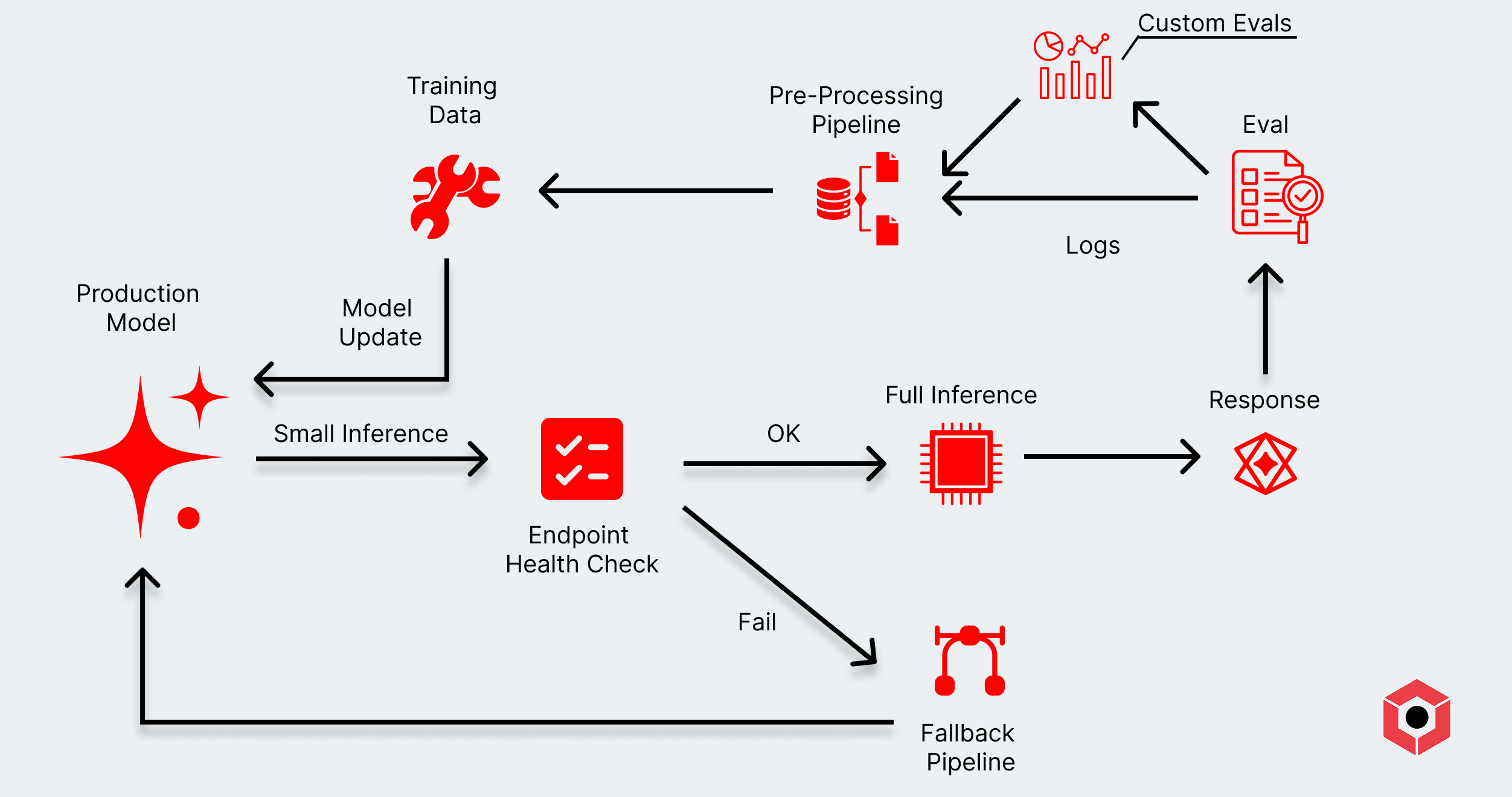
Here are a few examples where you might look at tweaking the infrastructure layer to further improve performance, feedback, and lower costs:
- Internal benchmarking harnesses determine app- or company-specific definitions of success. Rather than looking at public benchmarks and scores, custom harnesses create a feedback loop that aligns with KPIs associated with an application.
- Interstitial endpoint checks that determine what infrastructure is offering the best latency and throughput before executing model inference.
- Observability tools to monitor a workload’s performance and ensure it’s adhering to KPI requirements, such as uptime, response speed, and quality assurance.
- Evaluation to influence prior workflows to ensure that the workflow is constantly self-improving without the need to make manual tweaks.
- Data pipelines in a continuous learning machine that feeds response performance back into the start of the layer to update and influence a model’s behavior.
How customizing the AI system software layer leads to significantly better performance and quality
Say you’ve already created an exceptional set of models that accomplish your more complex tasks, and it’s led to a better user experience and lower operational costs. You still have to tackle the challenge of scaling workloads if your application is taking off. And that’s when you have to start looking below.
Building out the best inference setup doesn’t necessarily involve swapping in and out hardware. Companies with significantly more advanced expertise and a very high bar for performance and cost would start working at the actual model serving layer. That requires great data, and a strong team.
But it also requires a deep understanding of the model architecture itself and how to build and serve it yourself. And it also needs to include mechanisms for addressing every possible edge case—something only learned by having something in production and collecting constant feedback. We’re back to data again, but this time it’s coming from your application.
Here are a few examples where you could adjust the system software layer to pull off another layer of efficiency and improved performance:
- Load balancing and high availability to ensure that explicit fallbacks are in place in the case of excessive demand or downtime. If you’ve decided on a different setup of heterogeneous AI accelerators, you’d want to create a priority order—start with an inference accelerator, then fall back to a TPU, then a GPU.
- Custom kernels optimized for a given model to get the most performance, like CUDA kernels when working with Nvidia GPUs.
- Serving and orchestration to determine which models are available in a given workflow and in what order they operate. Frameworks like Ray provide additional layers of certainty around model operations through scheduling and access control. JAX, for example, can help with distributed systems for efficient parallelism.
- Intelligent batching that scales up and down to optimize throughput and cost. In usage spikes, you might want to cap the batch size at a point where latency remains very low and throughput maxes out. Alternatively, you might offer developers upfront the ability to tweak batch size at runtime to find the optimal setup.
- Dynamic usage that allows you to either cap or extend context lengths, or adjust batch size, in various scenarios. You might want to offer a priority line to a high-value customer during high-volume periods, and either rate limit or cut off extra performance variables for other users.
- Dynamic attention to evaluate an inbound request or prompt and choose the most efficient approach possible to achieve desired results.
- Efficient KV cache usage to re-use the work already done and shave off compute wherever possible. For a given user session, you might fix a KV cache at a point where performance drop-off is negligible with additional results.
All this still runs on top of the actual hardware that’s shuffling model parameters and executing the raw arithmetic to generate a token. And the universe of hardware—especially hardware optimized for inference—continues to grow.
How custom AI accelerators are powering the future of high-performance inference
Around the launch of ChatGPT and the first Llama model, we really only had GPUs to work with (unless you’re working at Google). Large companies build out massive stockpiles of GPUs, leading to major shortages for A100s and H100s. These were largely used for pre-training models like GPT-series or Llama-series models.
Many of these AI-powered applications are taking off. ChatGPT, for example, gets 2.5 billion requests per day. The companies that previously devoted most of their resources to training have to shift their focus to inference by using both existing GPUs and deploying new ones. Nvidia GPUs work, but there’s a limit to what they can do at the inference layer. They’re great at training, but they’re only good at inference. In a best-case scenario, you’re able to push out a few hundred tokens per second.
But there’s a large portfolio of hardware available for companies willing to muck around at the bare metal layer. Each might be good at certain workloads and fall short at others, and getting custom hardware—and implementing it in a smart way—is the last mile on improving performance and efficiency. You just have to be ready to get your hands dirty.
There’s an ever-growing number of options out there as new products in the market, either from the obvious providers, hyperscalers, or startups building custom accelerators. Each accelerator has its own tradeoffs, but workflows are evolving to a point where you can mix and match them.
You could batch accelerators into four-ish generalized categories:
- Nvidia GPUs are a tried-and-true system for running an AI workload (and serve as the ideal fallback if needed.)
- TPUs and AMD GPUs as alternatives depending on the scenario. AMD might be more effective for memory-hungry workloads, while TPUs can work well for disaggregated processing when using frameworks like JAX.
- Hardware from hyperscalers, like Amazon’s Trainium and Inferentia.
- Custom AI accelerators that are designed specifically for inference workloads of popular model types.
Ideally, any AI workload will mix and match to get to the best balance of performance and cost of operations. Each of the options outside Nvidia—particularly custom accelerators—are starting from a different set of goals. In our case, we specifically focused on transformers-based inference—but we’re far from the only option available, and it’s easy to try most emerging technology with available endpoints.
The whole process of determining the best hardware is a much, much longer discussion to have. We’ll address it in more depth in a blog post later in this series.
Where the customization all comes together
Fortunately, in most situations optimizing the experience around an AI workflow doesn’t involve mucking around in PyTorch code. Many services have either already optimized the workflows, or they provide simple high-level ways to customize deployments and abstract away everything that’s happening under the hood.
Most developers can instead just enjoy the benefit of years of work that has gone into these problems and can focus on just the upper layers. Two and a half years into the current generation of AI, we now have at least half a dozen services that brush everything under the rug.
But, as always, the cost of simplicity is losing flexibility to adapt to rapid changes in the industry. It also means being reliant on a given service and trusting that it’ll keep up with any new developments—and with its peers.
The speed of AI development is unlike any other emerging technology before it. Rather than see significant updates and innovation happening on a yearly—or longer—basis, new tools and techniques come out every month. A brand-new way to manage attention could come out tomorrow, and it would require adjustments at runtime. Or a new retrieval technique could come out and completely change existing enterprise search tools.
The most successful developers and organizations can adapt quickly to all these changes and stay ahead of their peers, and it’s optional how deep those optimizations go. But understanding and knowing how (and when) to turn the knobs can be the difference between creating a sustainable application—or getting left behind by the competition.


